Research
その他AI研究
感情AIに直接含まれないが、ラボとして取り組んでいるAI研究のテーマ群。
取り組んでいること
Affectosphere Group の中心は感情AIだが、研究を進める過程で隣接領域に立ち上がる問いも多い。マルチエージェント設計の一般化、LLMの内部表現の解明、教育・産業実装の汎用基盤など、感情を直接の対象としないが、感情AIの土壌となる技術研究をここに集めている。とりわけ、LLMがどのような世界知識をどう引き出すかという問題は、感情AIの内部理解研究と表裏一体であり、本領域の主要関心事となっている。
分かってきていること
LLMの内部知識を引き出す手法として、抽象的推論よりも具体的事例の連想想起のほうが信頼できるという性質が見えてきている。複数エージェントによる並列想起と投票の枠組みは、単一プロンプトでの推論よりも高い精度を達成しうる。また、名前から国籍を推定するような世界知識依存タスクでは、LLMが従来のニューラルモデルを全粒度で上回ることが確認されており、LLMの事前学習由来の世界知識を活用する設計の有効性が示されている。
Research notes
研究の物語
Affectosphere Group の中心は感情AIだが、研究を進める過程で隣接領域に立ち上がる問いも多い。感情AIを構築するための技術が、感情そのものとは独立した一般的問題に展開することがある。本領域は、感情AIの研究過程で派生した汎用的なAI研究テーマを集める場である。マルチエージェント設計の一般化、LLMの内部表現の解明、教育・産業実装の汎用基盤など、感情を直接の対象としないが、感情AIの土壌となる技術研究をここに位置づける。
とりわけ本領域で重視するのは、LLM内部の世界知識(world knowledge)がどう引き出されるかという問題である。LLMは事前学習で大量のテキストから世界に関する知識を獲得しているが、その知識を引き出すには適切なプロンプト設計と推論戦略が必要となる。連想記憶(associative memory)のように、ある手がかりから関連する知識を芋づる式に引き出す能力、世界知識を活用した推論能力、そしてどの形式の知識引き出しが信頼できるかという性質の解明は、LLMを実用に展開するうえで中心的な問題である。これは感情AIの内部理解研究と表裏一体であり、本ラボの基礎研究の両輪をなす。
Who Does This Name Remind You of?(LAMA, 2026)は、LLMの内部知識引き出し方を解析した代表的研究である。問題設定は、人名から本人の国籍を推定するというタスクだが、本研究の本質は「LLMはどのような知識をどう引き出すか」の解明にある。LAMAは、LLMに「この名前で思い出す有名人」を想起させ、その人物の国籍から元の名前の国籍を推定する。具体的には、Person Agent(人物想起)と Media Agent(娯楽・スポーツ想起)の2つのエージェントが並列に有名人を想起し、それぞれの想起結果から国籍を推定して、投票で最終決定する。99カ国の予測で精度 0.817 を達成した。
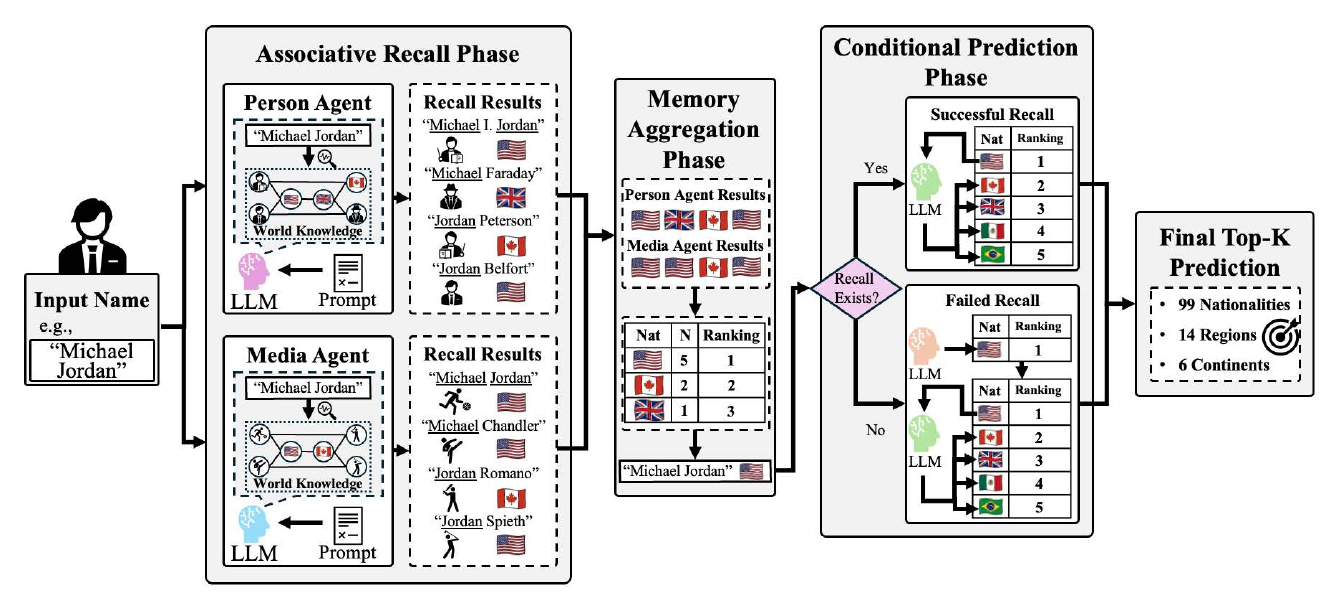
LAMAが示した重要な知見は、「抽象的推論よりも具体的事例の想起のほうが信頼できる」というLLM内部の性質である。「この名前はどの国の出身か?」と直接尋ねるよりも、「この名前で思い出す有名人は誰か?」と尋ねて、その人物から国籍を推定するほうが精度が高い。これは、LLMの知識が抽象的なルールではなく、具体的な事例の連想ネットワークとして格納されている可能性を示唆する。連想記憶を経由した間接的な推論は、LLMの実用展開において一般的に有効な戦略となりうる。本知見は、感情AIの内部理解においても、感情判断を直接尋ねるより関連する状況を想起させたほうが信頼性が高いという仮説に繋がる。
Nationality and Region Prediction from Names(2026)は、LAMAと同じく名前からの国籍予測を題材としつつ、より体系的な比較研究を展開した。従来のニューラルモデル(LSTM・Transformer・各種埋め込み手法など)6種と、LLMプロンプト戦略(zero-shot・few-shot・chain-of-thought など)6種を、国籍・地域・大陸という3つの粒度で網羅的に比較した。結果、LLMが全粒度で従来のニューラルモデルを上回り、その差は事前学習由来の世界知識に起因することが定量的に示された。
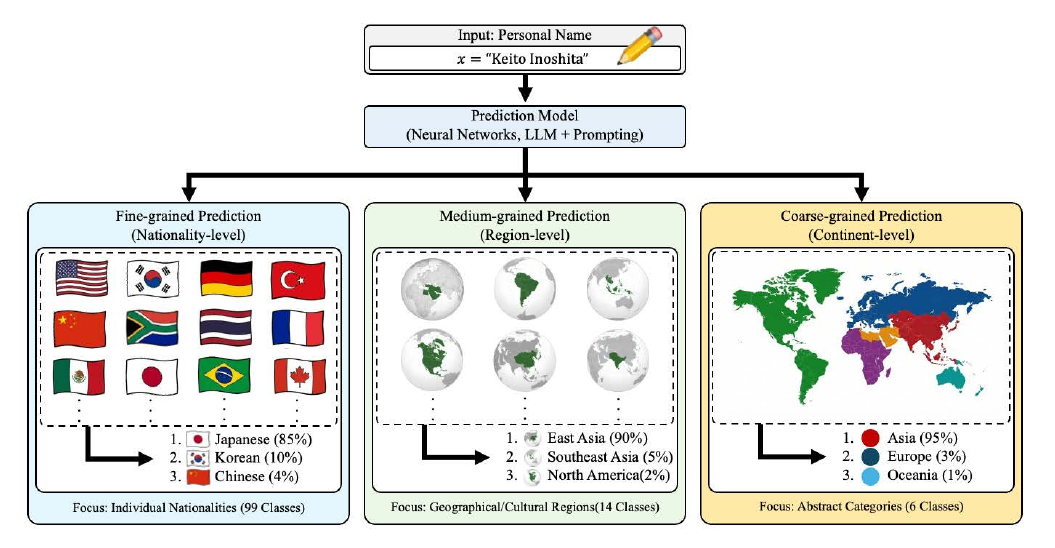
本研究の興味深い副次的発見は、LLMとニューラルモデルでは「誤り方の質」が異なるという点である。LLMの誤りは「近い地域への外し」が多く、例えば日本人名をベトナム人と予測するような、東アジア圏内での混同が典型的だ。一方、ニューラルモデルは高頻度クラス(米国・中国など)に偏った誤りを示し、訓練データの分布の偏りを直接反映する。誤り方の質的差は、両者の知識構造の違いを示しており、応用設計においてどちらを選ぶかの判断材料を提供する。世界知識を要するタスクではLLM、訓練データ分布の特性を活用するタスクではニューラルモデルといった、選択指針の確立に資する研究である。
本領域に集まる研究は、感情AIの直接の対象ではないが、感情AIの基礎技術と地続きである。LLMの内部知識引き出しの性質は、感情判断における不確実性研究と密接に関連する。マルチエージェント設計の方法論は、感情認識の Kairanban-IBC や心理支援の5エージェント討論と共通の設計思想を持つ。本領域は、感情AIから派生する一般的技術知見を蓄積し、それを再び感情AI研究へと還流させる「基礎技術の貯水池」として機能する。今後も、LLM・マルチエージェント・知識引き出しといったテーマで、研究を蓄積していく予定である。