Research
感情AIの内部理解
モデルが何を根拠に感情を判断しているかを解きほぐし、振る舞いの背後を可視化する。
取り組んでいること
感情AI、とりわけ大規模言語モデル(LLM)は、表面的にはラベルを当てているように見えても、その判断根拠は不透明である。主観性が本質的な感情タスクでは、モデルが人間の「迷い」や「揺らぎ」を再現できているか、自信(信頼度)と正しさが一致しているか、どのような知識をどう引き出して使っているか、を分布的・ベイズ的視点から定量化する必要がある。本領域では、出力ラベルの正解率ではなく、出力分布・不確実性・内部知識の引き出され方を解明する研究が広がっている。
分かってきていること
LLM は感情の代表ラベル(多数派の答え)は捉えるが、人間アノテーター間の「揺らぎの形」までは構造的に再現できないことが、大規模な分布解析から示されている。語彙的に明示された感情と、文脈推論を要する感情との間で乖離の質が異なり、後処理キャリブレーションには限界がある。一方、ベイズ的サンプリング(cSG-MCMC)とソフトラベル学習の組み合わせは、不確実性をデータ起因と知識不足起因に分離して扱える枠組みを提供し、主観的タスクでより誠実な不確実性表現を可能にしつつある。
Research notes
研究の物語
感情AI、とりわけ大規模言語モデル(Large Language Model, LLM)は、表面的にはラベルを正しく当てているように見えても、その判断根拠は不透明である。これは古典的な「ブラックボックス問題」と呼ばれる現象で、深層学習モデルの内部で何が起きているか、どの入力特徴に基づいて出力が決まったかが、人間には直接観測できない。感情AIにおいては、ブラックボックス性は単なる技術的不便さではなく、深刻な倫理的問題を孕む。なぜ「あなたは悲しんでいる」と判定したのかをAIが説明できなければ、利用者はその判定を受け入れるか拒否するかの判断材料を持たない。本領域は、感情AIの内部を解きほぐし、振る舞いの背後を可視化することを目指す。
感情タスクのもう一つの特殊性は、「正解」が客観的に定まらない主観的問題であることだ。「この文章は怒りか嫌悪か」という問いには、人間アノテーターのあいだでも答えが分かれる。したがって感情AIの評価は、単一の正解ラベルへの一致率ではなく、人間判断の分布をどれだけ忠実に再現するかで測られるべきである。具体的には、(i)モデルは人間の「迷い」や「揺らぎ」を再現できているか、(ii)自信(信頼度)と正しさが一致しているか(キャリブレーション)、(iii)どのような知識をどう引き出して判断に使っているか、という三つの観点から内部理解を進める必要がある。
ここで重要な概念として「キャリブレーション(calibration)」を整理する。キャリブレーションとは、モデルが出力する自信(確率値)と、実際の正答率の一致度合いを指す。例えば、モデルが「80%の自信でこの感情はAだ」と多数の予測を行ったとき、実際にそのうち80%が正解であればキャリブレーションが取れている。多くの深層学習モデルは過信(overconfidence)に陥り、90%の自信でも実際には70%しか正解できないという乖離が知られている。感情のように主観的なタスクでは、モデルが「迷っている」状態を正しく表現できるか、すなわち適切に低い自信を出力できるかが、信頼性の鍵となる。
LLMs Capture Emotion Labels, Not Emotion Uncertainty(2026)は、4モデル・64万応答にわたる大規模実験で、LLM が感情アノテーターとして人間の判断分布をどの程度再現できるかを検証した。実験は GoEmotions など複数の感情データセットに対して、LLM に多回数のアノテーションを行わせ、その出力分布と人間アノテーター集団の判断分布を分布距離指標(KLダイバージェンス・Earth Mover Distanceなど)で比較する設計を取った。結果、代表ラベルは概ね一致するが、アノテーター間の「揺らぎの形」、すなわち判断分布の形状までは再現できないことが示された。
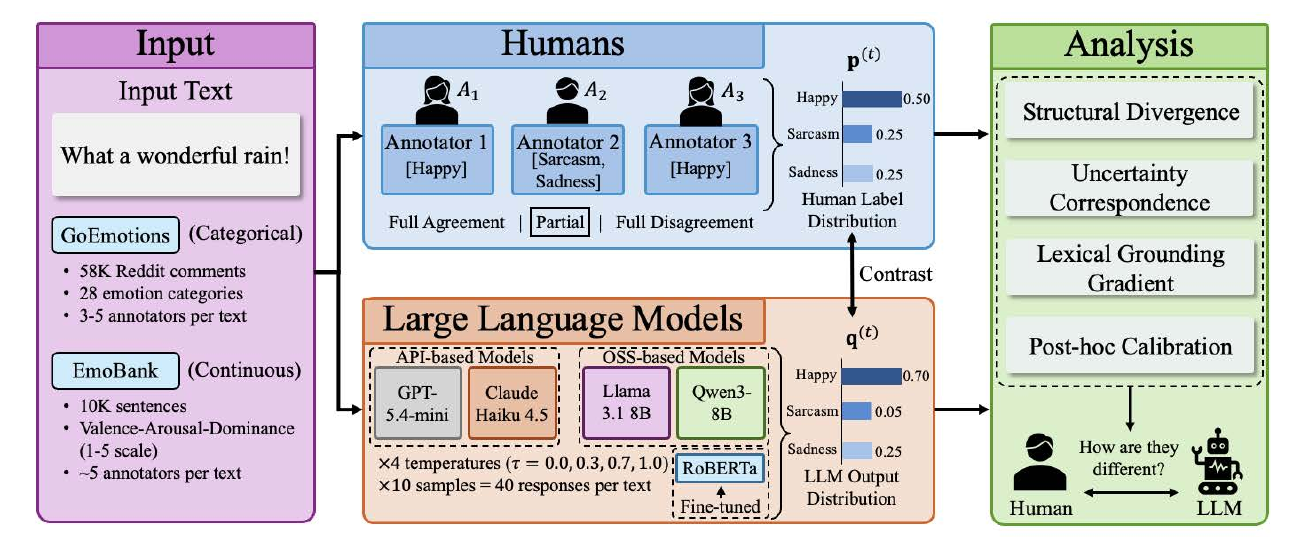
とりわけ興味深い発見は、感情カテゴリの種類によって乖離の質が異なる点である。「感謝」「愛」のように、語彙的に明示された感情(キーワードが文中に出現する感情)では、LLMの判断は人間と概ね一致する。一方、「承認」「実現」のように、文脈推論を要する感情(行間を読む必要がある感情)では、LLMと人間の判断分布が大きく乖離する。さらに、温度パラメータ調整やプラットスケーリングといった後処理キャリブレーション手法を試しても、乖離の縮減は最大14%にとどまった。これは、LLMの感情理解には構造的な限界が存在し、表面的なラベル予測精度だけでは捉えきれない深さがあることを意味する。
Uncertainty Decomposition via Cyclical SG-MCMC and Soft-label Learning for Subjective NLP(2026)は、こうした問題に対するベイズ的アプローチを提案した研究である。本論文の鍵概念は「認識的不確実性(epistemic uncertainty)」と「偶然的不確実性(aleatoric uncertainty)」の分解にある。認識的不確実性は、モデルが知識不足ゆえに判断を迷う種類の不確実性で、データを増やせば原理的に減らせる。偶然的不確実性は、データそのものに内在する曖昧性に起因する不確実性で、データを増やしても減らない。感情のような主観的タスクでは、両者が混在しているため、これを分離して扱うことが「誠実な不確実性表現」の鍵となる。
提案手法は、cSG-MCMC(cyclical Stochastic Gradient Markov Chain Monte Carlo, 周期的確率勾配マルコフ連鎖モンテカルロ)というベイズ的サンプリング手法と、ソフトラベル学習(人間アノテーター分布を確率分布として学習する手法)を組み合わせる。cSG-MCMCは、学習率を周期的に変動させながらモデルパラメータの事後分布からサンプリングする手法で、認識的不確実性を効率的に捉えられる。ソフトラベル学習は、偶然的不確実性をデータ側で表現する。両者を組み合わせることで、不確実性の二成分を構造的に分離できる。28感情の GoEmotions で、アノテーター分布との一致度・選択予測性能・カテゴリ別の不確実性相関のすべてで MC Dropout や Deep Ensemble といった既存ベイズ的手法を上回ることが示されている。
本領域の研究が示唆するのは、感情AIの内部理解には「正解率の向上」とは別の評価軸が必要だということである。具体的には、(i)分布的整合性(モデル出力分布と人間判断分布の一致度)、(ii)キャリブレーション品質(自信と正解率の一致度)、(iii)不確実性の構造的分解(認識的・偶然的の分離)、という三つの観点が、感情AIを実社会で使う際の信頼性指標として確立されつつある。これらの観点は、本ラボの他領域、特に応用開発における安全性設計や、倫理領域における説明責任の議論と密接に接続する。