Research
AIによる感情の認識
テキスト・音声・生理信号から感情の分布を推定する、基盤的な認識研究。一点推定ではなく、不確実性ごと扱う設計を志向する。
取り組んでいること
感情認識はテキスト・音声・生理信号・映像など多様なモダリティを対象とし、ポジティブ/ネガティブの二値判定から、皮肉のような裏表のある表現、ドライバーの心理状態、文脈依存の感情解釈まで対象が広い。単一モデルによる一点推定では、文化的多義性・アノテーター間の不一致・少数派の意見が均されてしまうため、近年は多視点・多専門家・多段推論を組み合わせる設計、認知科学に基づく因果構造の埋め込み、不確実性を含めた予測などが研究されている。
分かってきていること
感情認識の精度向上の鍵は、単一モデルでの一発予測ではなく、複数の視点・複数の専門家・複数の段階に推論を分解することにあると示されつつある。例えば、皮肉理解では「字面と本音の差分」「観察→規範→意図の認知連鎖」を明示的にモデル構造化する。運転支援では「知覚→判断→感情→行動」の因果連鎖を組み込む。LLM 同士が回覧板や井戸端会議のように合議することで、確信度の独走を抑える。これらの工夫は精度だけでなく、説明可能性と不確実性表現の質も改善している。
Research notes
研究の物語
感情認識(emotion recognition)は感情AIの中核タスクであり、テキスト・音声・生理信号・映像など多様なモダリティを対象とする。テキストからの感情認識はソーシャルメディア分析や顧客サポートで広く用いられ、音声からの感情認識はコールセンターや音声アシスタントに、生理信号(心拍・皮膚電気活動・脳波)からの感情認識は医療・ウェルビーイング応用に、映像からの感情認識はドライバー支援や教育評価に展開されている。各モダリティは異なる特徴を持ち、テキストは意味の豊富さで優位、音声は韻律情報、生理信号は意識下の感情状態、映像は表情と姿勢の動的情報をそれぞれ提供する。
感情認識の対象は、単純なポジティブ/ネガティブの二値判定から、皮肉のような裏表のある表現、ドライバーの心理状態、文脈依存の感情解釈まで広範に及ぶ。とりわけ困難なのは、表現と本意が一致しない場合である。皮肉(sarcasm)は字面ではポジティブだが意図はネガティブという典型例だ。文化的多義性も問題となる。日本語の「結構です」が肯定か拒否かは文脈依存だ。さらに、アノテーター間の不一致や少数派意見の無視といった、主観性に起因する問題が常に伴う。単一モデルによる一点推定では、これらの複雑性が均されてしまう。
近年の研究では、単一モデルでの一発予測ではなく、複数の視点・複数の専門家・複数の段階に推論を分解する設計が成果を挙げている。本領域の研究群は、(i)認知科学的な人間推論プロセスをモデル構造に埋め込むアプローチ、(ii)複数の LLM エージェントが合議する設計、(iii)Evidential Deep Learning などによる不確実性表現の組み込み、(iv)モダリティ特性に応じた軽量化と頑健性の確保、という4つの方向で展開している。以下、代表的研究を順に紹介する。
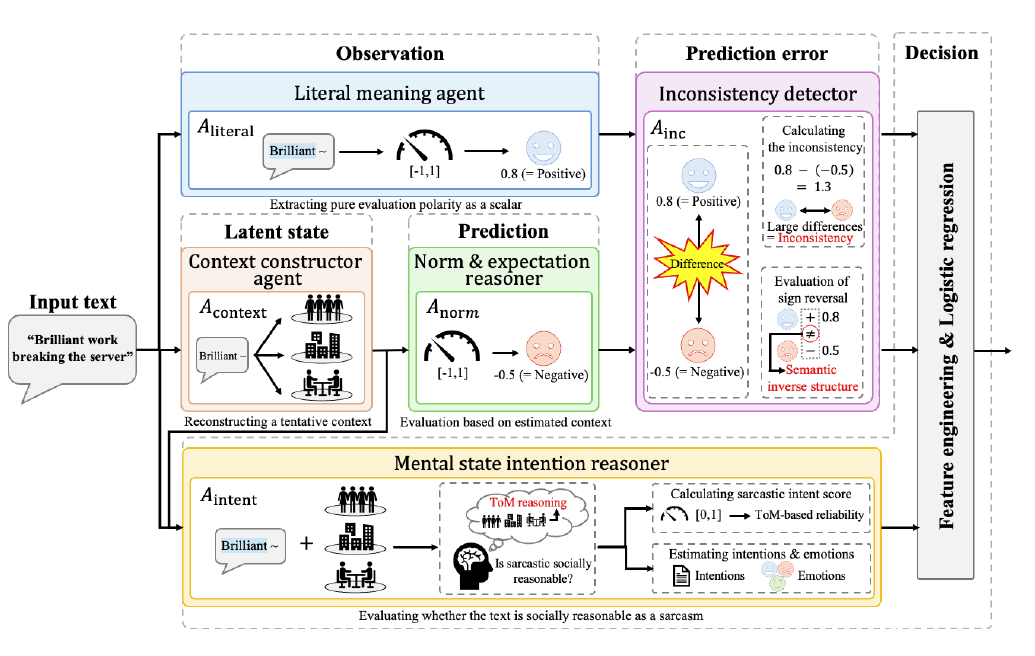
World Model Inspired Sarcasm Reasoning with LLM Agents(WM-SAR, 2026)は、皮肉理解を「観察→規範予測→ズレ検出→意図推論」という人間の認知過程に分解し、各段階を別の LLMエージェントが担う構成を提案した。ここでの「世界モデル(world model)」とは、人間が行動結果を予測するために頭の中に保持している現実の内部表現を指す概念である。皮肉は「世界モデルに基づく規範的予測」と「実際の発話」のずれによって認識される。本研究では、観察エージェントが状況を記述し、規範予測エージェントが「普通ならどう言うか」を予測し、ズレ検出エージェントが実際の発話との差分を抽出し、意図推論エージェントが背後の意図を推定する。最終判定は軽量な回帰モデルが行う。既存手法を上回る精度に加え、「どこでズレが生じたか」を構造的に説明できる解釈性を備える。
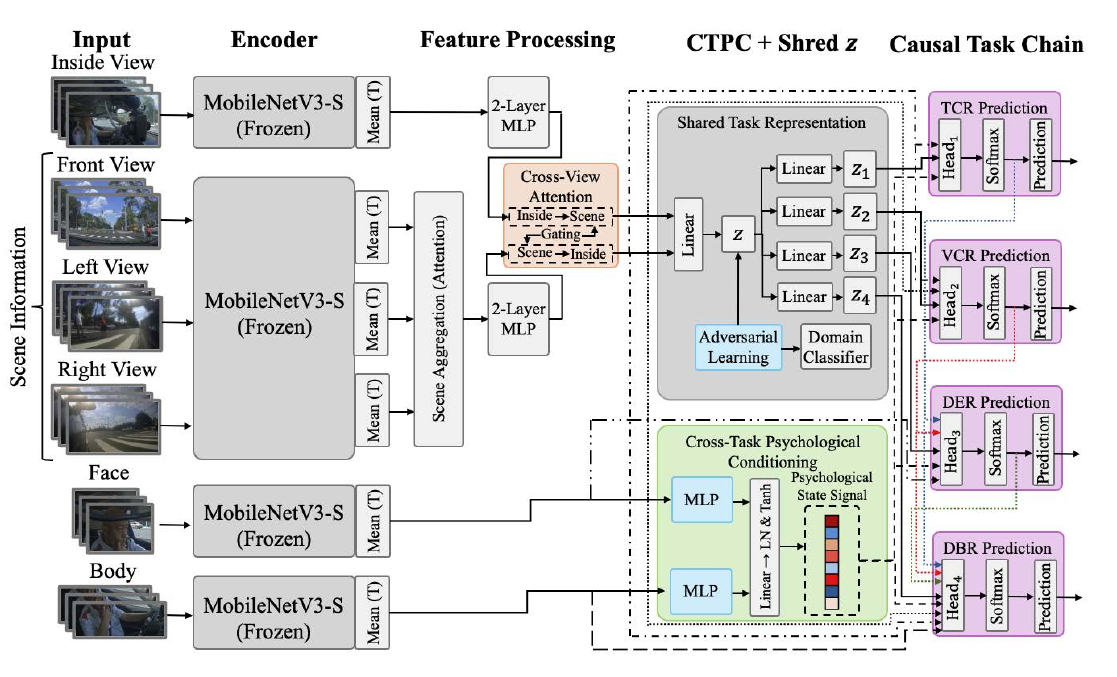
Cognitive-Causal Multi-Task Learning(CauPsi, 2026)は、運転支援の認識タスクに認知科学の知見を直接構造化した研究である。ここでの「認知因果連鎖(cognitive-causal chain)」とは、人間が行動を起こす際の「知覚→判断→感情→行動」という心理的プロセスの順序関係を指す。CauPsiは、交通状況認識・車両操作予測・感情推定・行動予測という4つのタスクを、この因果連鎖に従ったマルチタスク学習として連結する。具体的には、低層のタスクの中間表現が高層のタスクへの条件として伝播し、特にドライバーの顔・姿勢から推定した心理状態が全タスクに条件付けされる。約5Mパラメータと軽量ながら平均82.7%の精度を達成し、特に感情(+3.7%)と行動(+7.5%)で従来手法を改善した。認知科学を直接モデル構造に翻訳する研究の好例である。
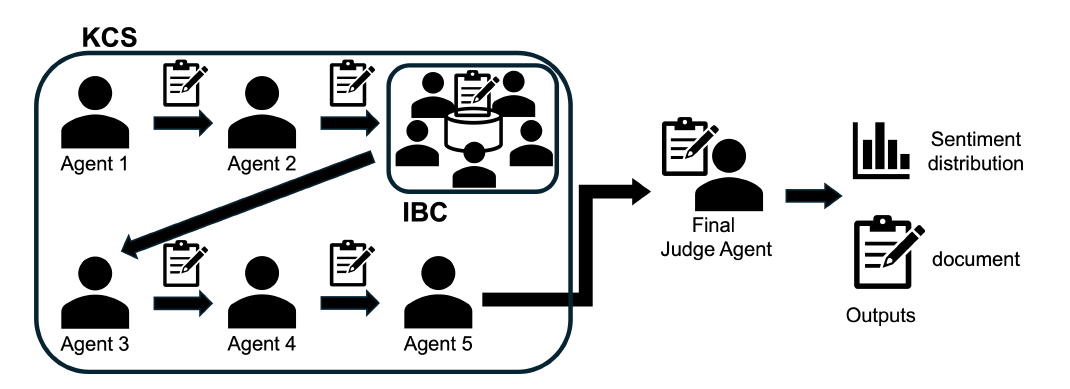
A Multi-Agent Probabilistic Inference Framework Inspired by Kairanban-Style CoT(2025)は、日本の文化的合議プロセスを機械的推論に持ち込んだユニークな試みである。「回覧板(Kairanban)」は、町内会で書類を順番に回し意見を書き加える日本の伝統的慣行で、本研究では Kairanban Chain of Stamps(KCS)として、複数のLLMが順番に意見を書き加える設計に翻訳された。続いて「井戸端会議(Idobata Conversation, IBC)」が、複数のLLMが自由に意見を交わす段階を担う。二段階の議論によって、確信度の独走(単一モデルの過信)を抑制しつつ予測のばらつきを保ち、より丁寧な感情推定を実現した。文化的合議プロセスがバイアス是正の機構として機能することを示した、興味深い設計研究である。
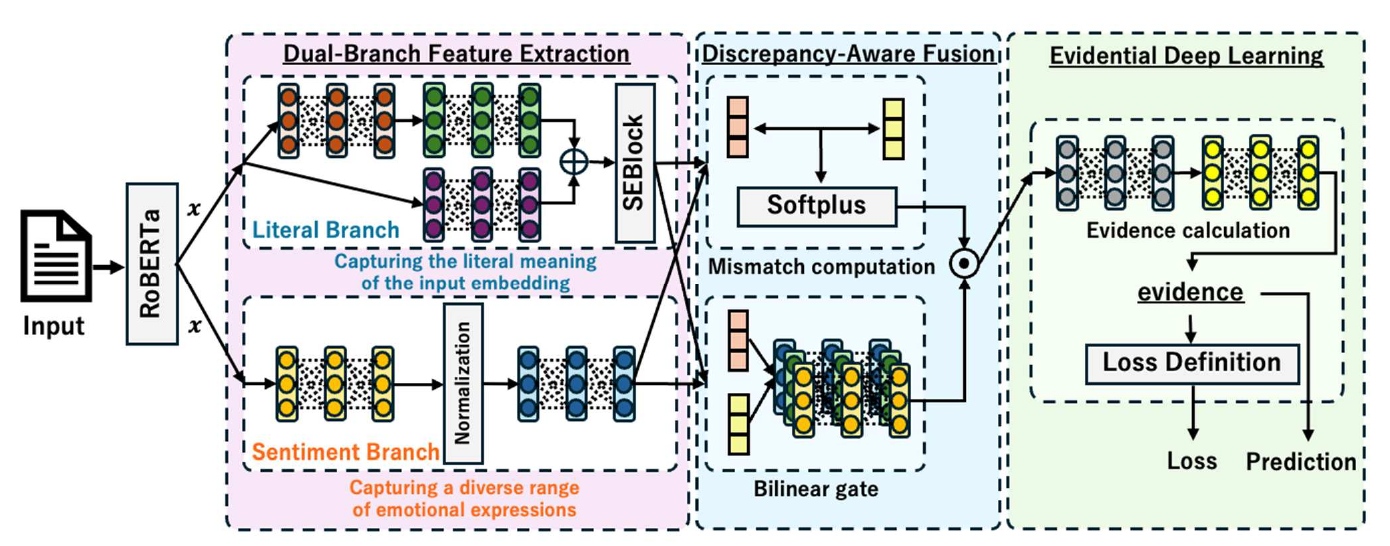
Dual-Branch Feature Extraction via Discrepancy-Aware Fusion with Evidential Deep Learning for Sarcasm Detection(DBDA-EDL, 2025)は、皮肉表現を「字面」と「本音」の二系統で並列に表現し、両者の不一致を明示的に取り出す設計を提示した。ここで導入される Evidential Deep Learning(EDL, 証拠的深層学習)は、通常の分類器が確率を出力するのに対し、ディリクレ分布のパラメータを直接出力することで、予測の自信度と不確実性を同時に表現できる手法である。DBDA-EDLは、字面表現と本音表現の差分(discrepancy)を融合特徴として取り出し、EDLによって予測の自信度を同時に出力する。曖昧な皮肉表現に対しては控えめな確信度を返す「正直に迷えるモデル」を実現している。
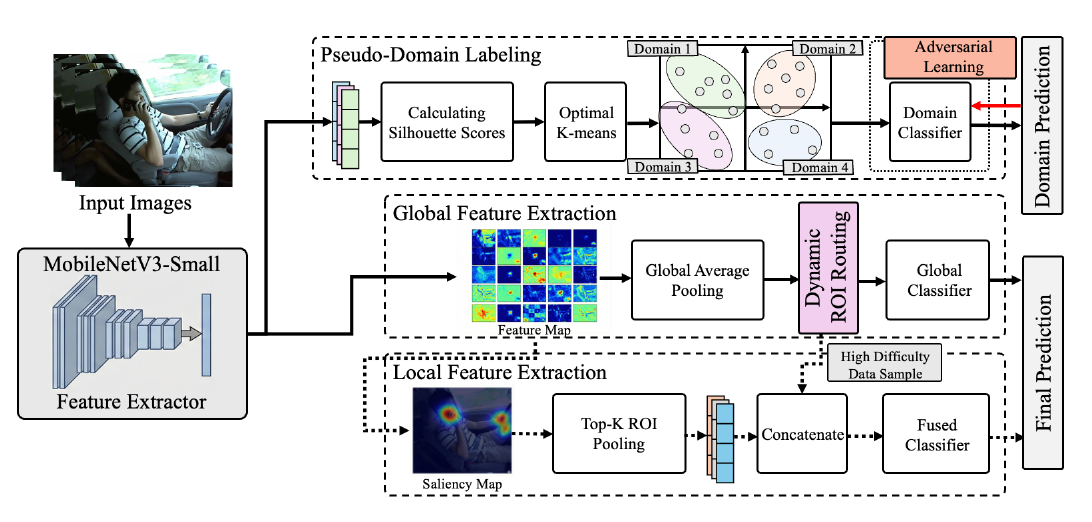
C-DIRA(2025)は、車載カメラ向けのドライバー行動認識を、軽量化と頑健性の両立という産業要件のもとで再設計した研究である。車載環境では、計算資源の制約・照明環境の多様性・運転者個人差・カメラ位置の変動など、研究室環境では見えない問題が山積する。C-DIRAは二つの工夫でこれに対処する。第一に「動的ROIルーティング」として、画像全体をまず判定し、難しい場面でのみ重要領域(Region of Interest)に絞って詳細処理する仕組みを導入する。第二に「ドメイン不変敵対的学習(domain-invariant adversarial learning)」として、ドライバーや照明環境の差を打ち消すよう敵対的に学習させる。わずか2Mパラメータで99.2%の精度と、ドメイン変動への頑健性を同時に達成した。
本領域の研究群が示唆するのは、感情認識の精度向上の鍵は単一モデルでの一発予測の改善ではなく、推論を「視点・専門家・段階」に分解する設計にあるということである。皮肉理解は字面と本音の二系統で(DBDA-EDL)、規範予測と意図推論の連鎖で(WM-SAR)、運転認識は認知因果連鎖で(CauPsi)、文化的合議プロセスで(Kairanban)、それぞれ精度・説明可能性・不確実性表現の質を同時に改善している。これらの工夫は、本ラボの「感情AIの内部理解」領域が示す問題意識、すなわち「正解率だけでない多面的評価」と直接接続しており、設計と評価の両側面で領域間の対話が進んでいる。