Research
感情データの拡張
曖昧で多義的な感情ラベルを、不確実性を保ったまま拡張・補完する手法を探る。少数アノテーションでも、忠実な学習を可能にする。
取り組んでいること
感情AIの学習には人手による感情ラベル付きデータが不可欠である。しかし収集には、心理的負担・プライバシー・アノテーターの属人性(個人偏向)、子どもや高齢者など特定集団からの収集困難性など、構造的かつ倫理的な制約が存在する。本領域では、属人的な収集に依存しない非属人的データ生成と、既存データを意味論的・分布論的に拡張する手法が研究されている。具体的には、大規模言語モデルによる合成、知識駆動の条件付け生成、ペルソナ条件付け、発達段階適応など多様なアプローチが並走している。
分かってきていること
LLM による感情データ生成は、単純な言い換えを超えて、幾何的・知識的・ペルソナ的・発達的な制御を組み合わせれば、実データに匹敵する分布整合性と多様性に到達できることが示されてきた。とりわけ、データが少ない感情領域を狙って生成する「方向制御」、人間の知識を統計的特徴として埋め込む「知識駆動」設計、人物像を多段で構築する「ペルソナ条件付け」が、分布整合性と多様性を同時に達成する鍵として浮かび上がっている。これらは倫理的に収集が困難な領域でも感情AIを実装する道を開きつつある。
Research notes
研究の物語
感情AIの学習には人手による感情ラベル付きデータが不可欠だが、その収集は単なる作業効率の問題ではなく、構造的かつ倫理的な制約に直面する。第一に、感情ラベル付与作業はアノテーターに心理的負担を強いる場合がある。痛み・悲しみ・恐怖を含むテキストや映像を繰り返し読み込み判定することは、二次的なメンタル被害を生む。第二に、感情データは個人の内面を直接記述するため、プライバシー保護の要請が極めて強い。第三に、子ども・高齢者・特定の文化集団など、倫理的に直接データを収集することが困難な対象がある。本領域では、こうした制約を回避しつつ、感情AIの学習に必要なデータをいかに確保するかが中心的な問いとなる。
ここで重要な概念整理として、「属人性(personality-dependent)」と「非属人性(personality-independent)」、そして「意味論的拡張(semantic augmentation)」を区別しておく。属人的データ収集とは、特定の人物から直接感情ラベルを取得する伝統的な手法であり、その人の主観や偏向(individual bias)が結果に直接反映される。非属人的データ生成は、特定個人に依存せずデータを合成する手法であり、LLM による生成や知識駆動の条件付け生成が代表例となる。意味論的拡張は、既存データの意味的・統計的構造を保ったまま分布を補完・拡張する手法であり、不均衡データの是正やドメイン適応に用いられる。本領域はこれら三つの概念を組み合わせ、倫理性と精度を両立する設計を探究する。
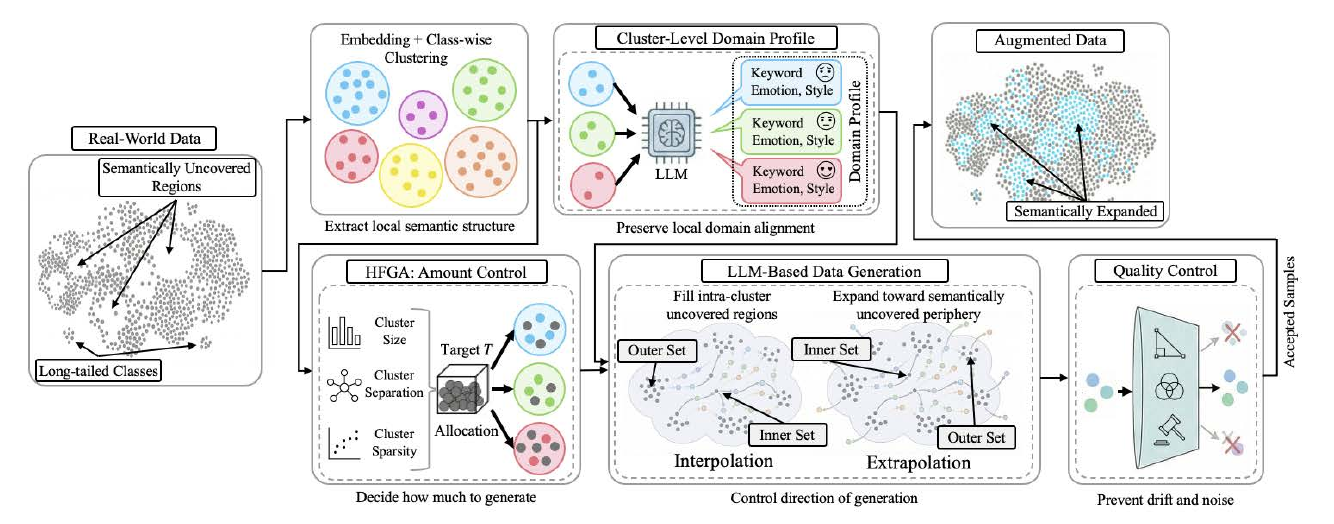
感情データセットには、特定のクラスの周辺が密で別のクラスは穴だらけという不均衡が常に存在する。例えば「喜び」「悲しみ」のような頻出感情には大量のサンプルが集まる一方、「軽蔑」「畏敬」のような稀少感情はわずかしか得られない。この不均衡は、機械学習モデルが少数派クラスを誤分類する原因となる。CIEGAD(Cluster-conditioned Interpolation/Extrapolation Geometric Augmentation for Data, 2025)は、この問題に対し、クラスタごとに「内挿(穴埋め)」と「外挿(周縁拡張)」の方向を幾何的に制御し、LLMに条件付き生成を行わせる手法である。具体的には、埋め込み空間内で既存サンプル間を内挿することで「穴」を埋め、クラスタの外側に外挿することで「周縁」を広げる。少数派クラスの F1 と Recall を安定して改善することが実証されている。
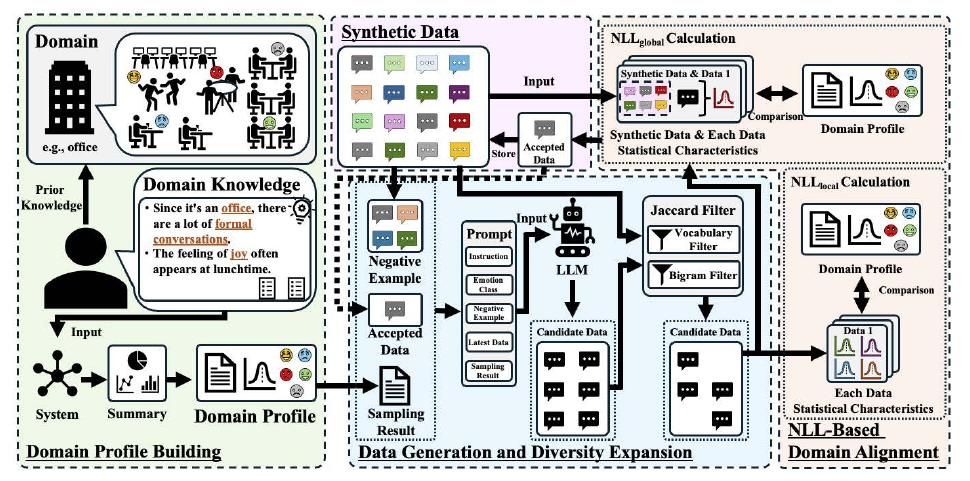
KDDA(Knowledge-Driven Data Augmentation, 2025)は、個人から感情データを直接取得せず、対象領域に関する人間の知識を統計的特徴に変換して LLMに条件付け生成させる枠組みである。例えば「職場のストレス」という領域であれば、その領域に固有の語彙頻度・典型的状況・代表的感情パターンなどを「ドメインプロファイル」として構築し、それを LLM への条件付けに用いる。生成データに対しては、語彙レベルの重複抑制と、負の対数尤度(Negative Log-Likelihood, NLL)に基づく統計的整合性評価を二重に課し、低品質サンプルを除外する。結果として、合成データのみで学習した感情分類器が12指標中9指標で実データに最も近い分布を達成した。属人的収集を回避する非属人的生成パイプラインの一例である。
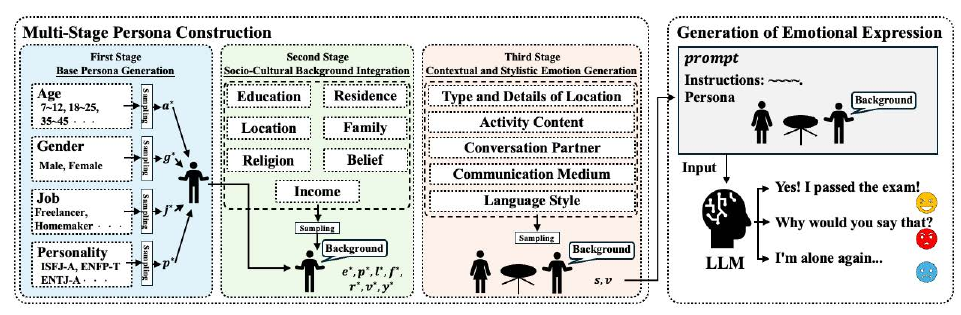
PersonaGen(2025)は、年齢・職業・性格・文化背景といった多層のペルソナ(persona, 設定された人物像)を段階的に LLMに与え、社会文化的に整合する感情表現を生成する手法である。同じ「悲しみ」でも、十代の学生と六十代の医師では語り方が異なる。PersonaGen は、属性 → 社会文化背景 → 状況文脈の3段階で条件を積み上げ、人物像に整合する自然な文体差を再現する。これにより、同一感情ラベルでも語る人物像に応じた多様な表現が生成され、下流タスクで実データに迫る性能を示した。多段ペルソナ条件付けは、表現の多様性と感情ラベルの整合性を同時に確保する設計として有効である。
Reproducing Developmental Features and Preserving Semantics in Child-Style Text Generation Using LLM(2025)は、子どもから直接データを収集することの倫理的困難に応答する研究である。大人向けの日本語文を小学1年から大学4年まで16段階の発達段階に書き換える設定で、文体変換の意味保持と発達的特徴の再現性を検証した。Few-shot(少数例提示)プロンプトで意味類似度 0.82-0.99 を保ちつつ、漢字・仮名比や読みやすさ指標が学年に応じて段階的に変化することが確認されている。子どもにアクセスせずに、教育用感情AIや児童向けコンテンツ設計に必要な「子どもらしい文体」を合成できる可能性を示した。
感情データ収集には、上記の技術的工夫だけでは解決しない倫理的問題が積み重なっている。第一に、収集者と被収集者の権力関係の非対称性がある。研究者・企業がデータ提供者から感情を引き出す関係は、本来的にインフォームド・コンセントが脆弱化しやすい。第二に、感情データの二次利用問題がある。ある研究で収集された感情データが、別の文脈で再利用される際、本人がその利用を予測できているとは限らない。第三に、特定集団からの収集困難性は、その集団を AI の恩恵から排除する結果につながりうる(代表性の欠如)。本領域の研究は、こうした倫理的問題と並走しつつ、非属人的生成によって両立点を探っている。
本領域の研究が示唆するのは、LLMによる感情データ生成は、単純な言い換えを超えて、幾何的・知識的・ペルソナ的・発達的な制御を組み合わせれば、実データに匹敵する分布整合性と多様性に到達できるということである。とりわけ、データが少ない感情領域を狙って生成する「方向制御」(CIEGAD)、人間の知識を統計的特徴として埋め込む「知識駆動」設計(KDDA)、人物像を多段で構築する「ペルソナ条件付け」(PersonaGen)、発達段階を制御する「年齢適応」(child-style)が、それぞれ異なる軸でデータの限界を補う。これらの技術は、倫理的に収集が困難な領域でも感情AIを実装する道を開きつつある。