Research
Other AI Research
Themes of AI research that are not directly part of affective AI but that our lab pursues.
What we work on
Affectosphere Group centers on affective AI, but research in adjacent areas often arises in the course of the work. Generalization of multi-agent design, elucidation of the internal representations of LLMs, and general-purpose foundations for educational and industrial deployment — work that is not directly aimed at emotion but forms the soil of affective AI is gathered here. The question of what world knowledge LLMs draw on, and how, is two sides of the same coin with research on understanding the inside of affective AI, and is a principal concern of this domain.
What we are finding
As a way to elicit internal knowledge from LLMs, the property is emerging that associative recall of concrete instances is more reliable than abstract reasoning. Frameworks of parallel recall and voting by multiple agents can achieve higher accuracy than reasoning from a single prompt. Furthermore, on world-knowledge-dependent tasks such as predicting nationality from a name, LLMs surpass conventional neural models at every granularity, confirming the effectiveness of designs that exploit the world knowledge LLMs acquire during pretraining.
Research notes
Research narrative
Affectosphere Group centers on affective AI, but research in adjacent areas often arises along the way. Techniques developed to build affective AI can extend to general problems independent of emotion itself. This domain is the place where general-purpose AI-research themes that branch off from the affective-AI work are gathered. We position research that is not directly aimed at emotion but forms the soil of affective AI — generalization of multi-agent design, elucidation of the internal representations of LLMs, and general-purpose foundations for educational and industrial deployment — here.
What this domain emphasizes most is the question of how the world knowledge inside LLMs is drawn out. LLMs acquire knowledge about the world from vast amounts of text during pretraining, but drawing on that knowledge requires appropriate prompt design and inference strategies. Capacities such as associative-memory-like chained recall from a cue, reasoning that exploits world knowledge, and elucidation of which forms of knowledge elicitation are reliable are central to deploying LLMs in practice. This is two sides of the same coin with research on the inside of affective AI and constitutes one of the two wheels of our lab's basic research.
Who Does This Name Remind You of? (LAMA, 2026) is a representative study that analyzed how LLMs draw on internal knowledge. The task is predicting a person's nationality from their name, but the essence of the work is in elucidating 'what knowledge LLMs draw on, and how.' LAMA prompts the LLM to recall 'famous people this name reminds you of' and then estimates the nationality of the original name from the recalled person's nationality. Specifically, two agents — a Person Agent (person recall) and a Media Agent (entertainment and sports recall) — recall famous people in parallel, each estimates a nationality from its recalled set, and a vote produces the final decision. The model achieves an accuracy of 0.817 on 99-country prediction.
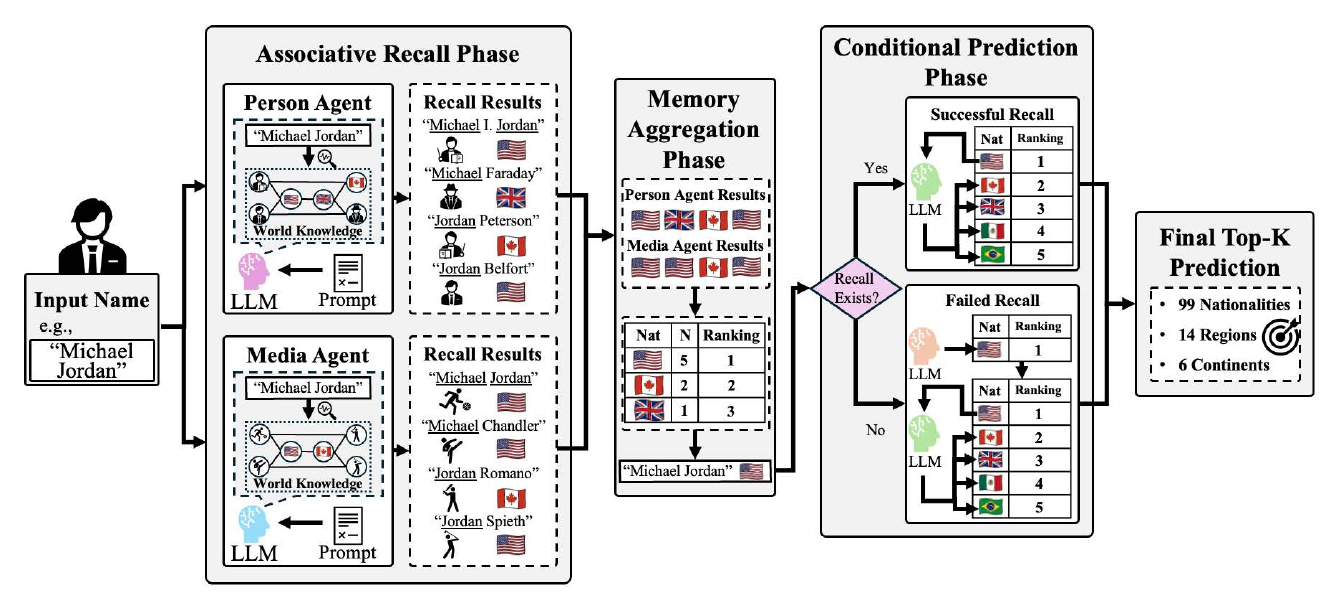
The important finding LAMA delivered is the internal property of LLMs that 'recall of concrete instances is more reliable than abstract reasoning.' Asking 'which country is this name from?' directly is less accurate than asking 'which famous person does this name remind you of?' and inferring nationality from that person. This suggests that LLM knowledge may be stored not as abstract rules but as an associative network of concrete instances. Indirect reasoning that passes through associative memory may be a generally effective strategy for deploying LLMs in practice. The finding extends to a hypothesis for affective-AI internal understanding as well: prompting the model to recall related situations may be more reliable than asking directly for an emotion judgment.
Nationality and Region Prediction from Names (2026) takes up the same nationality-from-name task as LAMA but develops a more systematic comparison. The work comprehensively compares six conventional neural models (LSTM, Transformer, various embedding methods, etc.) with six LLM prompting strategies (zero-shot, few-shot, chain-of-thought, etc.) at three granularities of nationality, region, and continent. The result is that LLMs surpass conventional neural models at every granularity, and the gap is quantitatively shown to derive from the world knowledge acquired during pretraining.
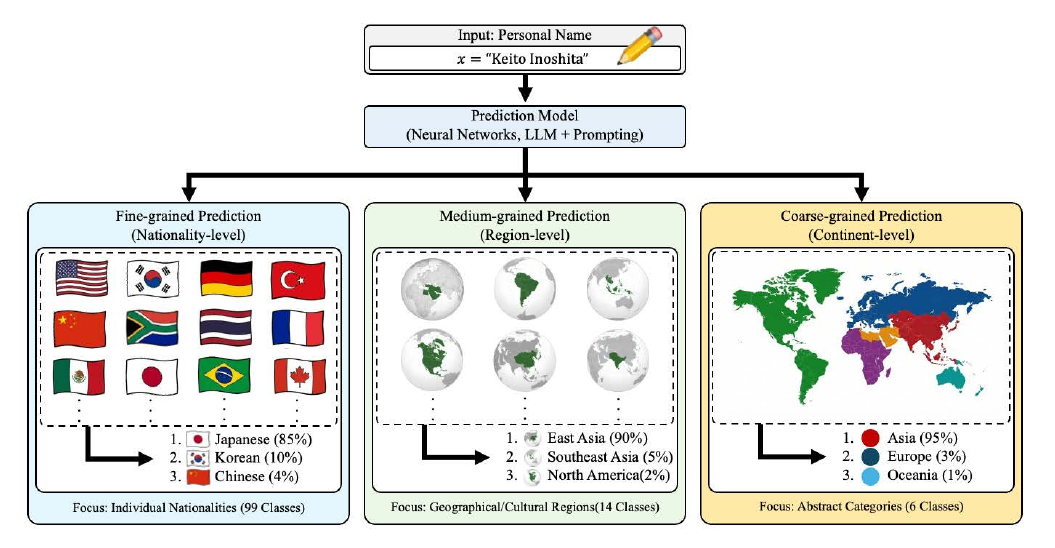
An interesting side finding of this work is that the 'quality of errors' differs between LLMs and neural models. LLM errors tend to be 'misses into nearby regions' — for example, predicting a Japanese name as Vietnamese, a typical East-Asian-region confusion. Neural models, in contrast, err in ways that lean toward high-frequency classes (the United States, China), directly reflecting biases in the training-data distribution. The qualitative difference in error patterns reflects a difference in knowledge structure between the two and provides material for choosing between them in applied design. The work supports the establishment of selection guidelines — LLMs for tasks that require world knowledge, neural models for tasks that exploit the characteristics of training-data distribution.
Research that gathers in this domain is not directly aimed at affective AI but is continuous with the basic technologies of affective AI. The properties of LLM internal-knowledge elicitation are closely related to uncertainty research on emotion judgment. The methodology of multi-agent design shares design ideas with Kairanban-IBC for emotion recognition and with the five-agent debate for psychological support. This domain functions as a 'reservoir of foundational technology' that accumulates general technical insight branching off from affective AI and feeds it back into affective-AI research. We will continue to accumulate work on themes such as LLMs, multi-agent design, and knowledge elicitation.