Research
Understanding the Inside of Affective AI
We unravel what models actually base their emotion judgments on and make the underlying behavior visible.
What we work on
Affective AI, and Large Language Models (LLMs) in particular, may look as if they are assigning labels correctly on the surface, yet the basis for their judgments is opaque. For emotion tasks, where subjectivity is essential, we must quantify — from distributional and Bayesian perspectives — whether models reproduce the 'hesitation' and 'wavering' of humans, whether confidence aligns with correctness, and how internal knowledge is elicited and used. This domain advances research that clarifies not just output-label accuracy but the shape of the output distribution, the structure of uncertainty, and how internal knowledge is brought to bear.
What we are finding
Large-scale distributional analyses show that LLMs capture the dominant emotion label (the majority answer) but cannot structurally reproduce the 'shape of wavering' among human annotators. The quality of the gap differs between lexically explicit emotions and emotions that require contextual inference, and post-hoc calibration has limits. Meanwhile, combining Bayesian sampling (cSG-MCMC) with soft-label learning provides a framework that separates data-borne from knowledge-borne uncertainty, enabling more honest uncertainty expression for subjective tasks.
Research notes
Research narrative
Affective AI, and Large Language Models (LLMs) in particular, may appear to assign labels correctly on the surface, yet the basis for their judgments is opaque. This is the classical 'black-box problem' of deep learning: what happens inside the model, and on which input features the output depends, cannot be directly observed by humans. In affective AI, black-boxness is not merely a technical inconvenience but harbors a serious ethical concern. If the AI cannot explain why it ruled 'you are sad,' the user has no basis for accepting or rejecting that ruling. This domain aims to unravel the inside of affective AI and make the underlying behavior visible.
Another distinctive feature of emotion tasks is that there is no objectively fixed 'correct answer' — they are subjective problems. The question 'is this text anger or disgust?' divides human annotators. Therefore, evaluation of affective AI should be measured not by agreement with a single ground-truth label but by how faithfully the model reproduces the distribution of human judgments. Concretely, internal understanding must be advanced from three perspectives: (i) whether the model reproduces human 'hesitation' and 'wavering,' (ii) whether confidence aligns with correctness (calibration), and (iii) what knowledge is elicited and how it is used to judge.
An important concept to organize here is 'calibration.' Calibration measures the degree to which a model's stated confidence (probability) matches its actual accuracy. For example, if a model predicts many cases as 'emotion A with 80% confidence' and 80% of those turn out correct, the model is calibrated. Many deep-learning models fall into overconfidence: they assert 90% confidence while being correct only 70% of the time. For subjective tasks such as emotion, whether the model can correctly express a 'hesitant' state — that is, whether it can output appropriately low confidence — is the key to reliability.
LLMs Capture Emotion Labels, Not Emotion Uncertainty (2026) examined, in a large-scale experiment spanning four models and 640,000 responses, the extent to which LLMs as emotion annotators can reproduce human judgment distributions. The design had LLMs annotate items in multiple emotion datasets including GoEmotions many times and compared the output distributions with the judgment distributions of human annotator populations using distributional metrics (KL divergence, Earth Mover Distance, etc.). The result: representative labels broadly agree, but the 'shape of wavering' among annotators — the shape of the judgment distribution — is not reproduced.
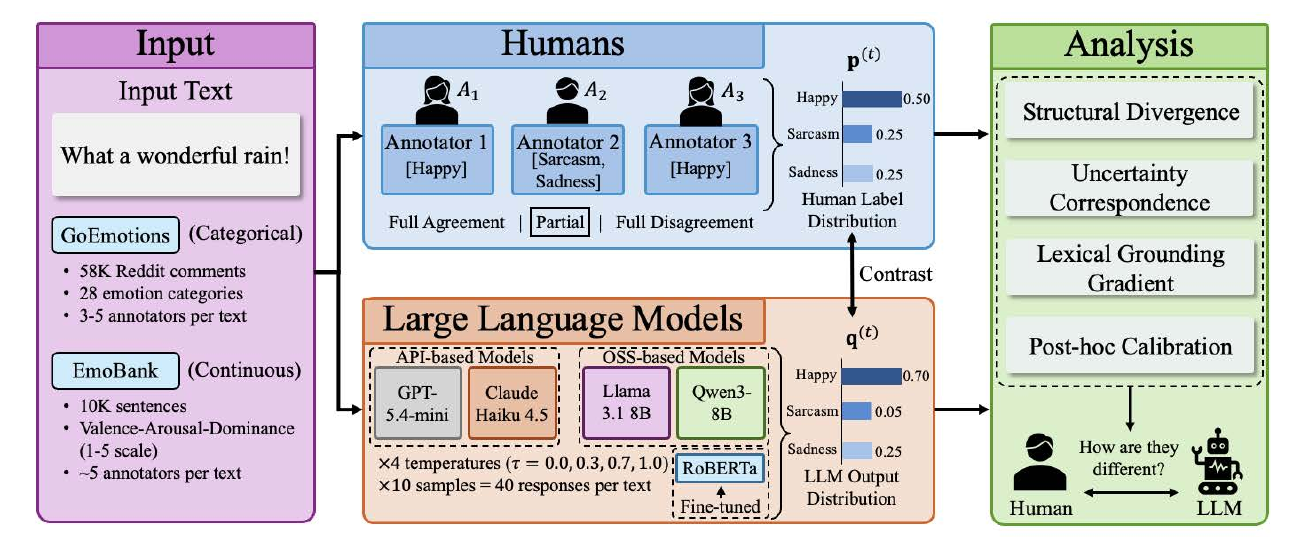
A particularly interesting finding is that the quality of the gap differs by emotion category. For emotions that are lexically explicit (where a keyword appears in the text), such as 'gratitude' and 'love,' LLM judgments broadly agree with humans'. For emotions that require contextual inference (where one must read between the lines), such as 'approval' and 'realization,' the LLM and human judgment distributions diverge widely. Furthermore, post-hoc calibration methods such as temperature scaling and Platt scaling reduce the gap by at most 14%. This means there is a structural limit to LLMs' understanding of emotion that cannot be captured by surface label-prediction accuracy.
Uncertainty Decomposition via Cyclical SG-MCMC and Soft-label Learning for Subjective NLP (2026) proposes a Bayesian approach to this problem. The key concepts are the decomposition into 'epistemic uncertainty' and 'aleatoric uncertainty.' Epistemic uncertainty is the kind that arises from the model's lack of knowledge and can in principle be reduced by adding data. Aleatoric uncertainty is intrinsic to the data and is not reduced by adding more data. In subjective tasks such as emotion, the two are mixed, and separating them is key to 'honest uncertainty expression.'
The proposed method combines cSG-MCMC (cyclical Stochastic Gradient Markov Chain Monte Carlo) — a Bayesian sampling technique that varies the learning rate cyclically while drawing from the posterior over model parameters — with soft-label learning that learns the human annotator distribution as a probability distribution. cSG-MCMC efficiently captures epistemic uncertainty, while soft-label learning expresses aleatoric uncertainty on the data side. Combining the two yields a structural decomposition of the two components of uncertainty. On 28-emotion GoEmotions, the approach surpasses existing Bayesian methods such as MC Dropout and Deep Ensemble on annotator-distribution agreement, selective prediction performance, and per-category uncertainty correlations.
The implication is that the internal understanding of affective AI requires evaluation axes distinct from 'improving accuracy.' Concretely, three perspectives are being established as reliability indicators when deploying affective AI in society: (i) distributional alignment (how well the model output distribution matches the human judgment distribution), (ii) calibration quality (how well confidence matches accuracy), and (iii) structural decomposition of uncertainty (the separation of epistemic and aleatoric components). These perspectives connect tightly to other domains in our lab, especially to safety design in applied development and accountability discussions in ethics.