Research
Emotion Recognition by AI
Foundational recognition research that estimates emotion distributions from text, speech, and physiological signals — aiming for designs that handle uncertainty rather than point estimates.
What we work on
Emotion recognition covers many modalities — text, speech, physiological signals, video — and many targets, from binary positive/negative judgment to two-faced expressions such as sarcasm, drivers' psychological states, and context-dependent emotion interpretation. Because single-model point estimates wash out cultural polysemy, annotator disagreement, and minority opinion, recent work studies designs that combine multiple perspectives, multiple experts, and multi-stage reasoning, embeds causal structure grounded in cognitive science, and produces predictions with uncertainty.
What we are finding
The key to improving emotion recognition appears to lie not in single-model one-shot prediction but in decomposing inference across perspectives, experts, and stages. For sarcasm understanding, the 'gap between literal and intended meaning' and the cognitive chain of 'observation → norm → intent' are explicitly built into the model structure. For driving support, the causal chain 'perception → judgment → emotion → action' is incorporated. LLMs deliberating among themselves — like a circulating notice or a casual chat — keep runaway confidence in check. These designs improve not just accuracy but also explainability and the quality of uncertainty expression.
Research notes
Research narrative
Emotion recognition is a central task in affective AI and covers many modalities including text, speech, physiological signals, and video. Text-based emotion recognition is widely used in social-media analysis and customer support; speech-based recognition appears in call centers and voice assistants; physiological-signal recognition (heart rate, electrodermal activity, EEG) is deployed in medical and wellbeing applications; and video-based recognition has spread to driver support and educational assessment. Each modality has distinct strengths: text excels in semantic richness, speech offers prosody, physiological signals reach subconscious affective states, and video provides dynamic information from facial expression and posture.
Targets range from simple binary positive/negative judgment to two-faced expressions such as sarcasm, drivers' psychological states, and context-dependent emotion interpretation. Particularly difficult are cases in which expression and intent diverge. Sarcasm is the prototypical example — positive on the surface, negative in intent. Cultural polysemy also matters: whether the Japanese 'kekkō desu' is acceptance or refusal depends on context. Further complications include annotator disagreement and the neglect of minority opinion. Single-model point estimates wash out all of this complexity.
Recent work has succeeded with designs that decompose inference across multiple perspectives, multiple experts, and multiple stages rather than producing one-shot predictions from a single model. Research in this domain proceeds in four directions: (i) approaches that embed cognitive-scientific accounts of human reasoning into the model structure, (ii) designs in which multiple LLM agents deliberate, (iii) the incorporation of uncertainty expression via methods such as Evidential Deep Learning, and (iv) lightweighting and robustness tailored to modality characteristics. Below we introduce representative studies in turn.
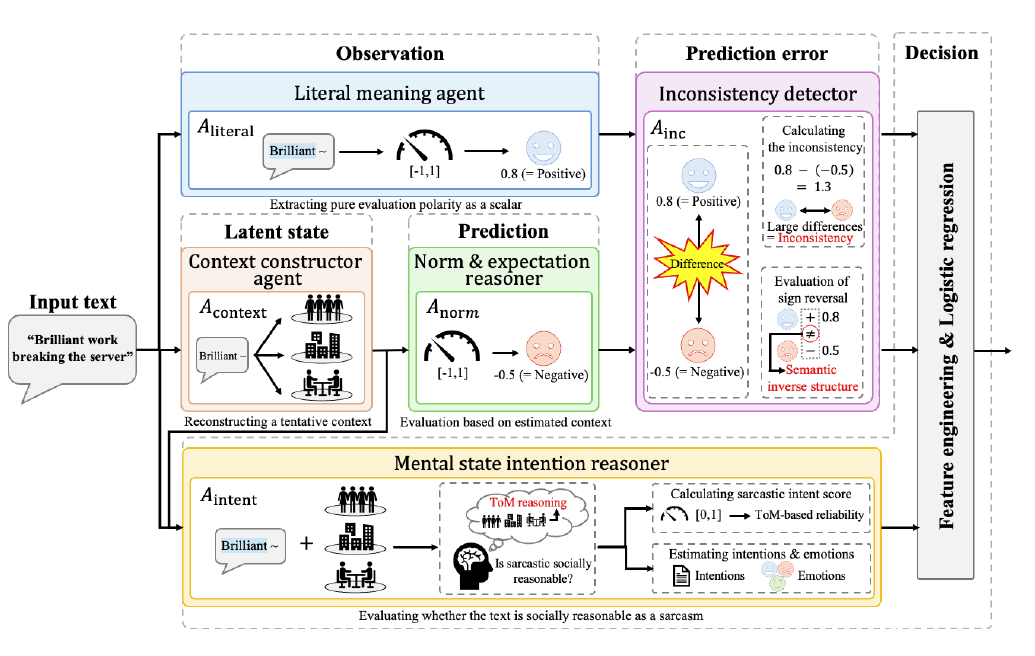
World Model Inspired Sarcasm Reasoning with LLM Agents (WM-SAR, 2026) decomposes sarcasm understanding into the human cognitive process of 'observation → norm prediction → gap detection → intent inference,' and assigns each stage to a separate LLM agent. The notion of a 'world model' here refers to the internal representation of reality that humans maintain in order to predict the outcomes of actions; sarcasm is recognized through the gap between a 'norm-based prediction grounded in the world model' and the actual utterance. The observation agent describes the situation, the norm-prediction agent predicts 'what one would normally say,' the gap-detection agent extracts the difference from the actual utterance, and the intent-inference agent estimates the underlying intent. A lightweight regression model makes the final decision. Beyond surpassing existing methods in accuracy, the system can structurally explain 'where the gap arose.'
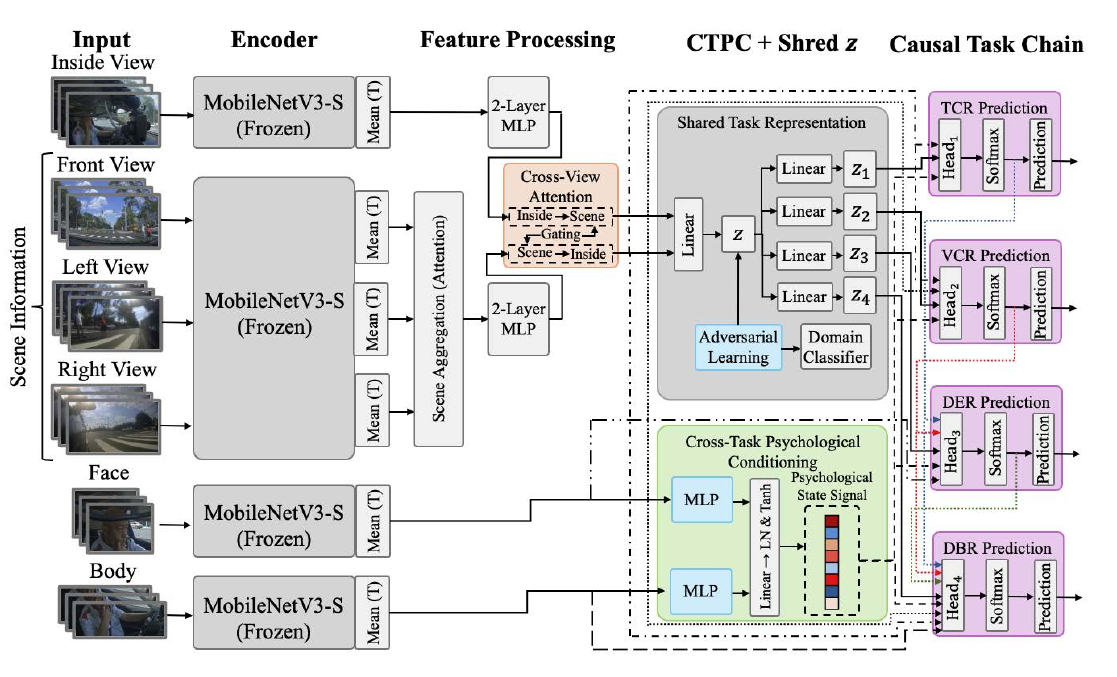
Cognitive-Causal Multi-Task Learning (CauPsi, 2026) directly structures cognitive-scientific insight into driving-support recognition tasks. The 'cognitive-causal chain' here refers to the ordered psychological process — perception → judgment → emotion → action — that humans go through when acting. CauPsi links four tasks — traffic-situation recognition, vehicle-operation prediction, emotion estimation, and behavior prediction — as multi-task learning that follows this causal chain. Specifically, the intermediate representations of lower tasks propagate as conditions to higher tasks, and in particular the psychological state estimated from the driver's face and posture conditions all tasks. With about 5M parameters, the model achieves 82.7% average accuracy and improves over prior methods especially on emotion (+3.7%) and behavior (+7.5%). It is a fine example of translating cognitive science directly into model structure.
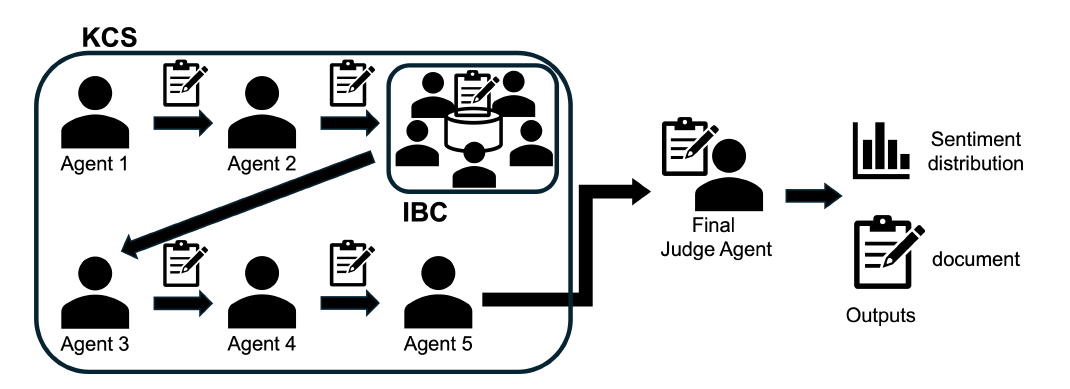
A Multi-Agent Probabilistic Inference Framework Inspired by Kairanban-Style CoT (2025) is a distinctive attempt that imports a Japanese cultural deliberation process into machine reasoning. The 'kairanban' is a Japanese tradition in which a document is passed in turn around a neighborhood association so members can add their opinions, and the paper translates this into the Kairanban Chain of Stamps (KCS), a design in which multiple LLMs append opinions in turn. This is followed by 'idobata conversation' (IBC), a stage in which multiple LLMs exchange opinions freely. The two-stage discussion suppresses runaway confidence (overconfidence by a single model) while preserving variance in predictions, achieving more careful emotion estimation. It is an interesting design study showing that a cultural deliberation process can function as a bias-correcting mechanism.
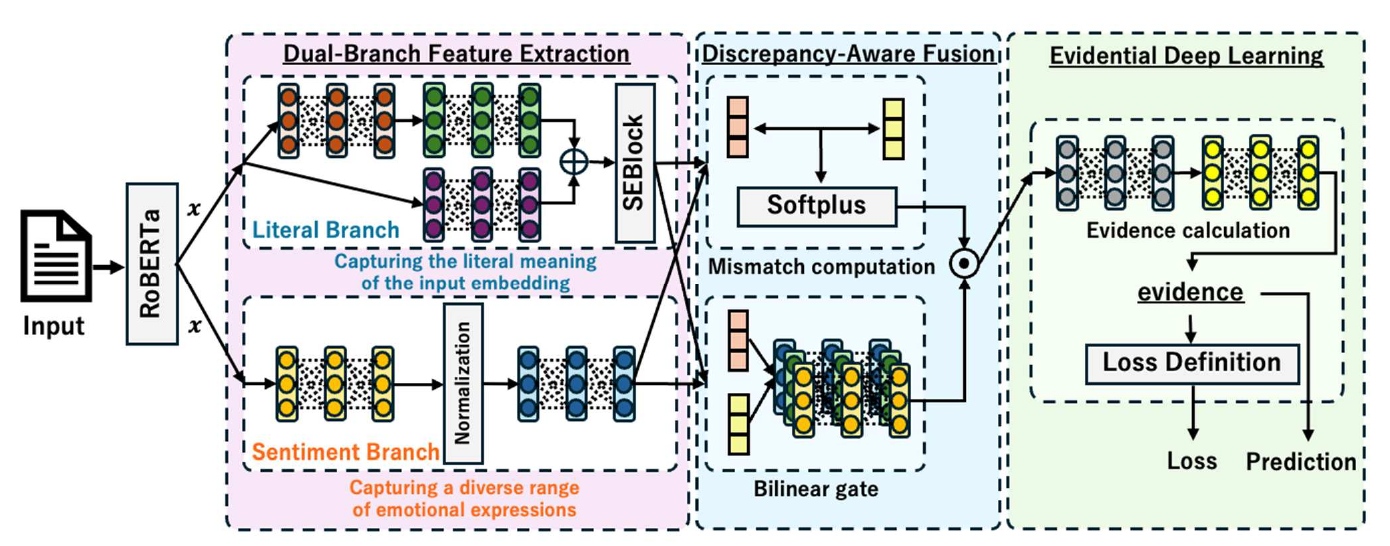
Dual-Branch Feature Extraction via Discrepancy-Aware Fusion with Evidential Deep Learning for Sarcasm Detection (DBDA-EDL, 2025) represents sarcasm in two parallel streams — 'literal' and 'intended' — and explicitly extracts the mismatch between them. The Evidential Deep Learning (EDL) introduced here is a method that directly outputs the parameters of a Dirichlet distribution rather than ordinary class probabilities, simultaneously expressing predictive confidence and uncertainty. DBDA-EDL extracts the discrepancy between literal and intended representations as a fused feature and uses EDL to output predictive confidence at the same time. For ambiguous sarcasm, it realizes an 'honestly hesitant model' that returns a modest confidence.
C-DIRA (2025) redesigns driver-behavior recognition for in-vehicle cameras under the industrial requirement of jointly achieving lightweighting and robustness. In-vehicle environments pile up problems that are invisible in the lab: limited compute, diverse lighting, individual driver differences, varying camera positions. C-DIRA addresses these with two ideas. First, 'dynamic ROI routing' first classifies the entire image and only narrows down to important regions (Regions of Interest) for difficult scenes. Second, 'domain-invariant adversarial learning' adversarially trains the model to cancel out differences in driver and lighting environment. With only 2M parameters, the model achieves 99.2% accuracy together with robustness to domain shift.
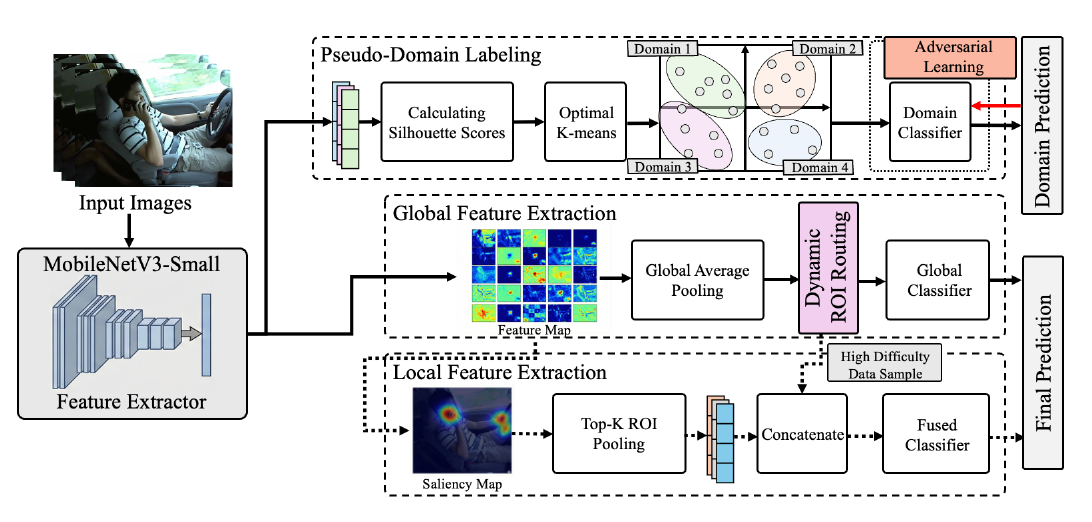
The implication is that the key to improving emotion recognition lies not in improving single-model one-shot prediction but in decomposing inference across 'perspectives, experts, and stages.' Sarcasm understanding improves via two streams of literal and intended (DBDA-EDL) and via the chain of norm prediction and intent inference (WM-SAR); driving recognition improves via the cognitive-causal chain (CauPsi) and via a cultural deliberation process (Kairanban). Each simultaneously improves accuracy, explainability, and the quality of uncertainty expression. These designs connect directly to the concern raised in our lab's 'Understanding the Inside of Affective AI' domain — that evaluation must be multifaceted, not merely accuracy-based — and dialogue between design and evaluation is advancing across domains.