Research
Augmenting Emotional Data
We explore methods that augment and complete ambiguous, polysemous emotion labels while preserving their uncertainty — enabling faithful learning even from sparse annotation.
What we work on
Affective-AI training requires emotion-labeled data produced by humans, yet collection is constrained both structurally and ethically: psychological burden on annotators, privacy, annotator idiosyncrasy (individual bias), and difficulty of collecting data from particular populations such as children or older adults. This domain studies non-individual data generation that does not rely on personalized collection, together with methods that augment existing data semantically and distributionally. Approaches include LLM-based synthesis, knowledge-driven conditional generation, persona conditioning, and developmental-stage adaptation, all running in parallel.
What we are finding
LLM-based emotion-data generation can — beyond mere paraphrasing — reach distributional alignment and diversity comparable to real data when geometric, knowledge-based, persona-based, and developmental controls are combined. 'Directional control' that targets underpopulated emotional regions, 'knowledge-driven' designs that embed human knowledge as statistical features, and multi-stage 'persona conditioning' have emerged as keys to achieving distributional alignment and diversity simultaneously. These open paths to deploying affective AI even in areas where collection is ethically difficult.
Research notes
Research narrative
Affective-AI training requires emotion-labeled data produced by humans, but collection is not merely a matter of workflow efficiency — it runs into structural and ethical constraints. First, emotion annotation can impose a psychological burden on annotators: repeatedly reading and judging text or video laced with pain, sadness, and fear can produce secondary mental harm. Second, since emotional data describes a person's interior directly, demands for privacy protection are extreme. Third, there are populations — children, older adults, specific cultural groups — from which direct collection is ethically difficult. This domain centers on the question of how to secure the data that affective AI needs while honoring these constraints.
It is useful to organize three concepts: 'personality-dependent' versus 'personality-independent' collection, and 'semantic augmentation.' Personality-dependent collection is the traditional approach of obtaining emotion labels directly from specific people; their subjectivity and individual bias enter the result directly. Personality-independent generation synthesizes data without depending on specific individuals — LLM-based generation and knowledge-driven conditional generation are representative. Semantic augmentation supplements and extends distributions while preserving the semantic and statistical structure of existing data, and is used for imbalance correction and domain adaptation. This domain combines these three concepts to seek designs that satisfy both ethics and accuracy.
Emotional datasets always carry imbalance: dense around some classes and full of holes around others. Frequent emotions such as 'joy' and 'sadness' attract large numbers of samples, while rare emotions such as 'contempt' and 'awe' yield only a few. This imbalance causes machine-learning models to misclassify minority classes. CIEGAD (Cluster-conditioned Interpolation/Extrapolation Geometric Augmentation for Data, 2025) addresses this by geometrically controlling the direction of 'interpolation (filling holes)' and 'extrapolation (extending peripheries)' within each cluster and asking an LLM to perform conditional generation. Concretely, interpolating between existing samples in the embedding space fills holes, and extrapolating outside the cluster widens the periphery. The approach stably improves F1 and recall on minority classes.
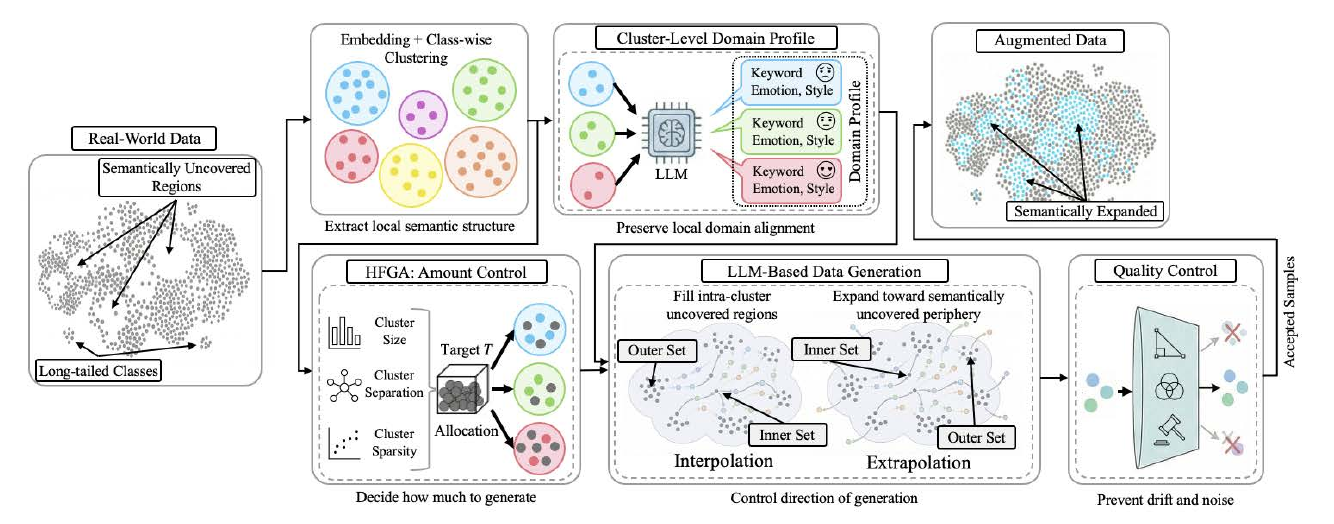
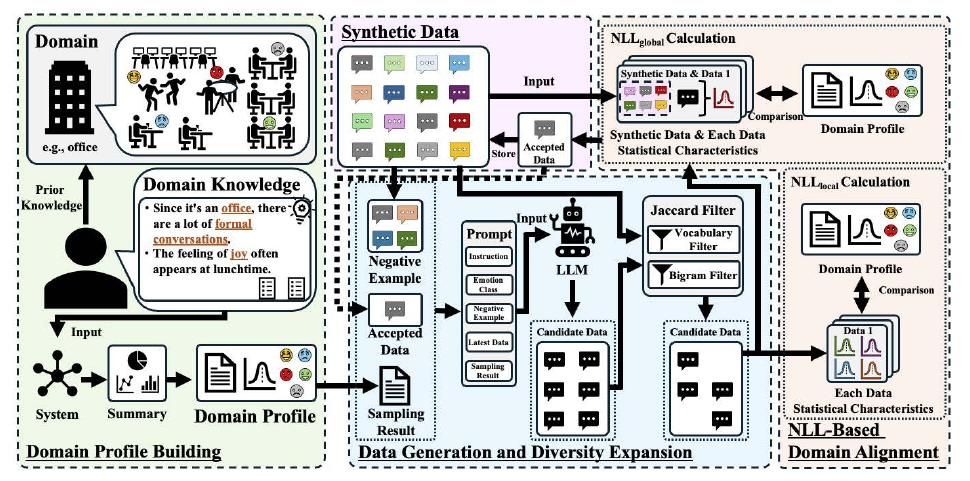
KDDA (Knowledge-Driven Data Augmentation, 2025) is a framework that, instead of collecting emotion data directly from individuals, converts human knowledge about a target domain into statistical features and uses them to condition LLM generation. For a domain such as 'workplace stress,' it builds a 'domain profile' from features specific to that domain — vocabulary frequencies, typical situations, characteristic emotion patterns — and uses it to condition the LLM. Generated data is doubly filtered by lexical-level overlap suppression and statistical consistency evaluation based on Negative Log-Likelihood (NLL), removing low-quality samples. As a result, an emotion classifier trained solely on synthetic data achieved the closest distribution to real data on 9 of 12 metrics — an example of a personality-independent generation pipeline that avoids personality-dependent collection.
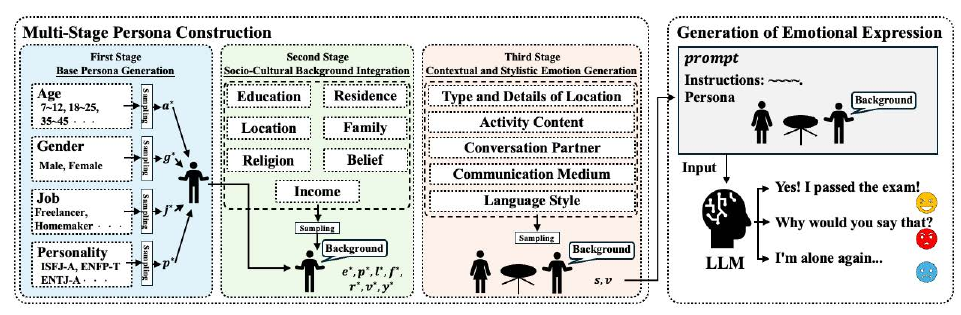
PersonaGen (2025) is a method that progressively conditions an LLM on multi-layer personas — age, occupation, personality, cultural background — to generate emotion expressions that are socio-culturally consistent. Even 'sadness' is articulated differently by a teenage student and a sixty-year-old physician. PersonaGen stacks conditioning in three stages — attributes, socio-cultural background, situational context — and reproduces stylistic differences consistent with the persona. As a result, the same emotion label yields diverse expressions appropriate to the character speaking, and downstream tasks achieve performance approaching real data. Multi-stage persona conditioning is effective for jointly securing expressive diversity and emotion-label consistency.
Reproducing Developmental Features and Preserving Semantics in Child-Style Text Generation Using LLM (2025) responds to the ethical difficulty of collecting data directly from children. Adult-oriented Japanese sentences are rewritten across sixteen developmental stages from first grade through fourth-year university, and the work examines semantic preservation and the reproducibility of developmental features. With few-shot prompting, semantic similarity is maintained at 0.82–0.99 while kanji-to-kana ratios and readability indices change in step with grade level. Without accessing children directly, the approach shows the feasibility of synthesizing the 'child-like' style needed for educational affective AI and children's content design.
Beyond these technical maneuvers, emotional data collection carries ethical problems that they alone cannot resolve. First, asymmetric power between collector and provider: the relation in which researchers or companies elicit emotion from a data provider inherently weakens informed consent. Second, secondary-use problems: emotional data collected for one study is often reused in another context where the provider could not have anticipated that use. Third, difficulty of collection from specific populations can result in excluding those populations from the benefits of AI (lack of representativeness). Research in this domain runs in parallel with these ethical issues and seeks balance points through personality-independent generation.
The implication is that LLM-based emotion-data generation, when combined with geometric, knowledge-based, persona-based, and developmental controls, can — beyond mere paraphrasing — reach distributional alignment and diversity comparable to real data. In particular, 'directional control' that targets underpopulated emotional regions (CIEGAD), 'knowledge-driven' designs that embed human knowledge as statistical features (KDDA), 'persona conditioning' that builds personas in multiple stages (PersonaGen), and 'age adaptation' that controls developmental stage (child-style) each complement data limitations along different axes. These techniques are opening paths to deploying affective AI even in domains where collection is ethically difficult.