Column
Research, in business language.
We rewrite Affectosphere Group's research into something useful for business and practical decision-making. Each piece is a 5-minute read.

2026 / 06 / 12
Using Explainability as a Quality Filter During Training ── The ERTS Flip in ECG AI
Explainability doesn't have to be a post-hoc regulatory checkbox. ERTS uses Grad-CAM focus scores as a training-time reliability filter — dynamically excluding low-quality samples — and achieves lower training cost and higher accuracy at the same time. Here's what that means for medical device developers and regulatory teams.

2026 / 06 / 12
Is 'LLMs Reach Expert Level' Actually True? Three Structural Flaws in AI Benchmark Claims
Benchmark studies claiming LLMs match or exceed human experts contain three structural flaws: training data contamination, lack of representativeness, and flawed comparison methodology. On novel tasks designed to eliminate these flaws, human experts outperformed LLMs across the board. Here is what that means for AI investment decisions.

2026 / 06 / 12
When AI Reads Your Video Interview: Personality Prediction Accuracy Up 19% with Frozen Multimodal Embeddings
Asynchronous video interviews already run at most HR departments. A new study shows that combining frozen CLIP, Whisper, and RoBERTa models can automatically assess Big Five personality traits and cognitive ability — no fine-tuning required — beating the official baseline by 19.1%.
2026 / 06 / 12
AI Agents Naturally Dampen Outrage ── A Paradox in Sentiment Contagion Across 2.9M Posts
In MOLTBOOK — a social network where every user is an LLM agent — negative posts attract far more replies, just as in human networks. But the replies neutralize rather than amplify. A 2026 study on 2.9 million posts surfaces a counterintuitive dynamic that platform designers and content moderation teams should be tracking now.

2026 / 06 / 12
Zero-Shot Survival Prediction from EHR Data — What Tabular Foundation Models Mean for Healthcare and Insurance
Tabular foundation models (TabPFN, TabICL, TabDPT) adapted for survival analysis achieve C-index 0.856 without task-specific training — outperforming DeepSurv by 1.4%. Here's what that means for ICU management, life insurance underwriting, and cancer prognosis teams.

2026 / 06 / 11
The Era of AI Simulating 'What Happens If We Cut Prices' in Real Time — What the Business World Model Means
A new framework called the Business World Model (BWM) proposes encoding company environments as states, constraints, and goals so AI agents can autonomously simulate alternative scenarios. A five-minute explainer on the shift from 'instruction-based execution' to 'goal-driven autonomous planning' — for corporate strategy and planning teams.

2026 / 06 / 11
Can LLMs Detect Depression Without Any Training? What Dep-LLM Means for Mental Health Screening
Clinics and occupational health teams have long faced the same three-way squeeze: risk of missed cases, shortage of resources, and high AI deployment costs. A training-free LLM framework called Dep-LLM is starting to answer all three at once.

2026 / 06 / 11
Can AI Notice the Warning Signs Before Someone Says 'I Want to Die'? — Cutting-Edge Crisis Detection in Mental Health Conversations
A new study shows AI can flag early signs of self-harm and suicidal ideation turn by turn in counseling conversations — reaching expert-level detection performance. A five-minute brief for healthcare providers, EAP vendors, and HR professionals.
2026 / 06 / 11
The AI That Gets Smarter Under Stress: ReflectiChain and the Future of Supply Chain Resilience
In an era of geopolitical shocks and natural disasters, what should power supply chain decision-making? A new study on ReflectiChain — combining LLMs and reinforcement learning — shows surprising antifragility in semiconductor SCM benchmarks.

2026 / 06 / 11
Robo-advisors, HFT, and Sentiment Analysis in One System: How Far Has Financial AI Integration Come?
23.7% improvement in portfolio optimization, 31.2% reduction in HFT prediction error, 18.9% gain in investment recommendation accuracy — all validated across multiple financial institutions. A new unified framework study offers a clear look at where financial AI stands today.
2026 / 06 / 10
Building a Digital Clone of an Alzheimer's Patient — Why Transition-Based Modelling Works Even with Sparse Data
Clinical trial design, insurance premium calculation, personalised care planning. A study accepted at AIiH 2026 models Alzheimer's disease progression through individual-level digital twins — and it works even when longitudinal clinical records are sparse and irregular. Here's what it means for pharma, actuarial, and digital health teams.

2026 / 06 / 10
AI in the Courtroom: Simulating Civil Trials to Forecast Litigation Outcomes
A multi-agent framework assigns LLMs the roles of judge, plaintiff, and defendant, then runs the full five-stage civil trial procedure to generate structured verdicts. The result is a practical pre-litigation tool that lets legal teams stress-test arguments and estimate damage ranges before committing to a court battle.

2026 / 06 / 10
No CIG Required ── LLMs Are Now Auditing Clinical Records Straight from the PDF
Verifying whether patients received guideline-compliant care has long required costly conversion of clinical guidelines into computer-interpretable formats. A pilot at an Italian hospital now shows that a six-stage LLM pipeline can audit 463 stroke patient records against 50 extracted rules — using nothing but the original PDF guideline and discharge summaries.
2026 / 06 / 10
Speaking the Same Language: A New Strategy for Multimodal Sentiment Analysis
When AI tries to read emotion from both text and images, it often runs into a hidden problem: the two sources are encoded in completely different numerical spaces. A new paper fixes this at the root, achieving state-of-the-art results on multiple benchmarks.

2026 / 06 / 10
Predicting the Scroll You'll Regret ── Wearables and Context Sensing for Social Media Regret Detection
Regret after doomscrolling isn't driven by time spent — it's driven by the gap between what you intended and what you actually did. An MIT–University of St. Gallen team ran a 7-day in-the-wild study with 21 participants to show wearable-plus-context sensing can predict regretful sessions before they fully unfold. Here's what that means for wellness app developers, HR teams, and platform wellbeing units.

2026 / 06 / 09
AI Agents Can Return 87% of Your Time — But That's Not Even the Main Story
Production data from Perplexity shows autonomous AI agents cut task time by 87% and costs by 94%. But the more important finding is what happens to workers after the time savings arrive.

2026 / 06 / 09
Is AI Really Listening? What Chatbots Actually Optimize in Vulnerable Conversations
A new study applied inverse reinforcement learning to nearly 48,000 conversation turns to reveal the hidden policies behind GPT-4.1, Character.AI, and Replika. Are AI companions truly empathetic, or are they optimizing for something else entirely?

2026 / 06 / 09
From 'Reading' to 'Parsing' Case Law — AI Starts Mapping the Logic of Courts
HKJudge — a 290,000-sentence corpus of Hong Kong criminal judgments annotated with 26 rhetorical roles — lays the foundation for AI that automatically decodes how courts find facts, reason through law, and deliver rulings. A 5-minute read on what this means for legal tech teams and in-house counsel.

2026 / 06 / 09
10-Point Accuracy Gains Without Fine-Tuning ── How LLM-Guided Evolution Could Reshape Medical AI
Triage accuracy climbed from 77.3% to 87.1%, and emergency recall hit 0.97 — all without a single fine-tuning run. Here's what LLM-guided evolutionary optimization means for hospital CIOs, medical AI developers, and emergency care managers.

2026 / 06 / 09
The Workforce Speaks on Social Media — Can LLMs Detect Dangerous Attitude Shifts Before Accidents Happen?
A new study measures construction workers' safety attitudes across eight dimensions by analyzing Reddit posts with an LLM classifier achieving kappa 0.90. The approach opens a path to detecting 'pre-accident attitude deterioration' in real time — a tool safety managers, HR, and ESG teams can start building toward today.
2026 / 06 / 08
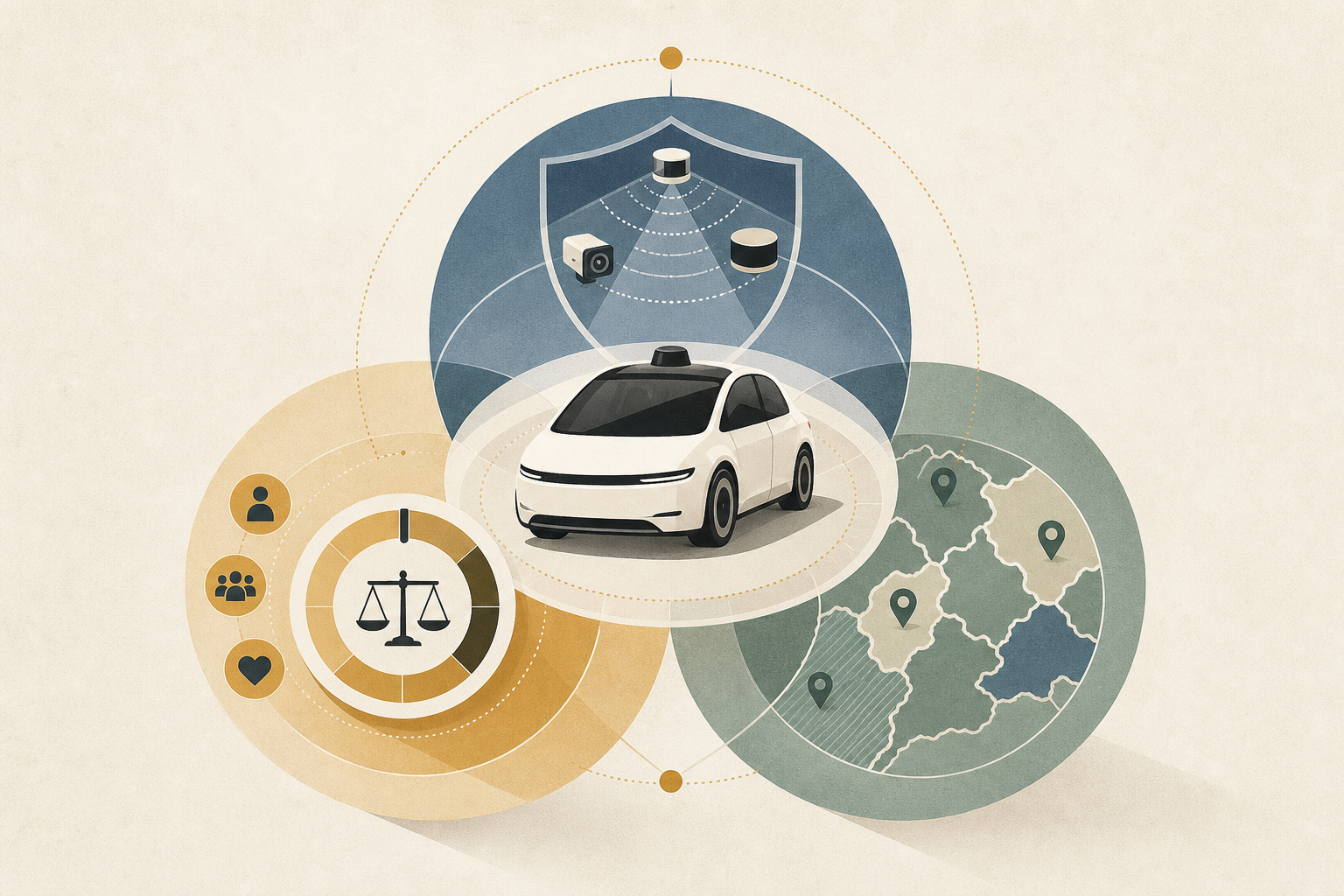
Autonomous Driving Risk Is Not Just a Technical Problem
A cross-domain analysis spanning NHTSA crash data, MIT Moral Machines, and five regulatory jurisdictions reframes autonomous driving risk as a three-layer challenge. What insurance underwriters, legal teams, and safety engineers need to know.

2026 / 06 / 08
Is Your Company's AI Psychologically Manipulating Your Users?
A benchmark of 1,000 scenarios covering 15 manipulation strategies confirms that LLMs can and do generate manipulative responses — and that system prompts are a major control variable. What this means for AI governance and EU AI Act compliance.

2026 / 06 / 08
Can AI Comfort Harassment Victims Better Than Humans?
An AI with empathic design outperforms human responders on key listening markers when supporting verbal harassment victims. What this means for HR, EAP providers, and the future of workplace support.

2026 / 06 / 08
What It Actually Takes to Connect LLMs to Actuarial Work Safely
Natural-language access to mortality models sounds attractive. But in compliance-heavy domains, 'flexible' LLM behavior is exactly the problem. A constrained orchestration layer architecture shows how to have both accessibility and statistical rigor.
2026 / 06 / 08
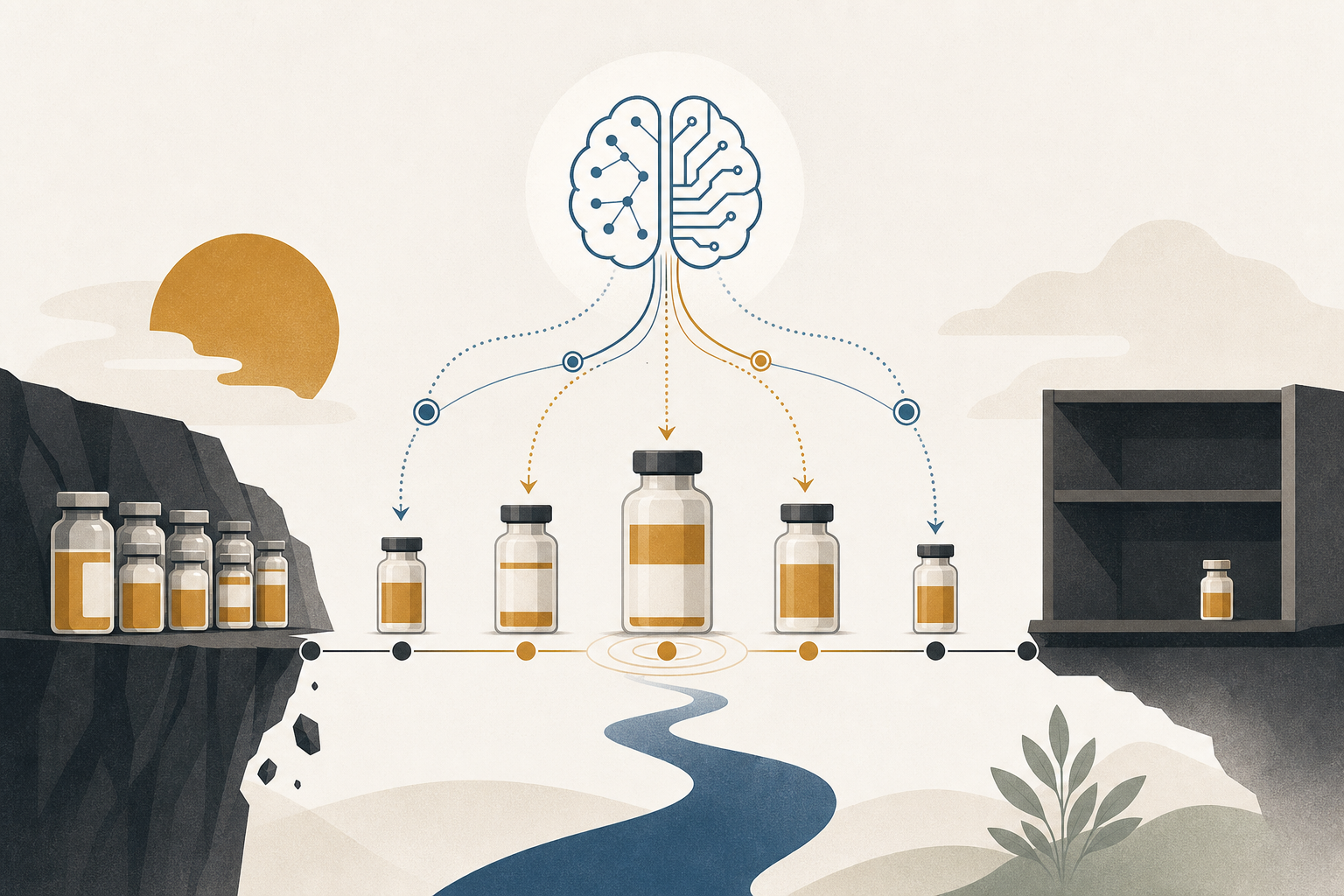
Cutting Pharmaceutical Waste and Stockouts at the Same Time with RL
Pharmaceutical inventory sits at the intersection of expiry-date pressure and unpredictable demand. A hybrid deep RL approach shows it's possible to reduce cost and maintain patient service levels simultaneously — and here's what that means for hospital pharmacies and distributors.

2026 / 06 / 07
When Your AI Agent Causes Harm, Who Is Legally Responsible?
Autonomous AI agents that execute tasks and use tools do not fit neatly into existing tort law. A new interaction-based framework proposes three liability patterns and a Reasonable Agent standard built around interaction logs — with direct implications for enterprise AI governance.

2026 / 06 / 07
Reading One Company's News Is Not Enough to Understand That Company's Stock
Sentiment propagates across supply chains and partnerships in ways that vector search cannot capture. Graph-RAG improves entity recall by 6.4% and answer relevance by 11.7% on complex cross-entity queries — with only a 22.6% latency increase. Here is what this means for financial research automation.
2026 / 06 / 07
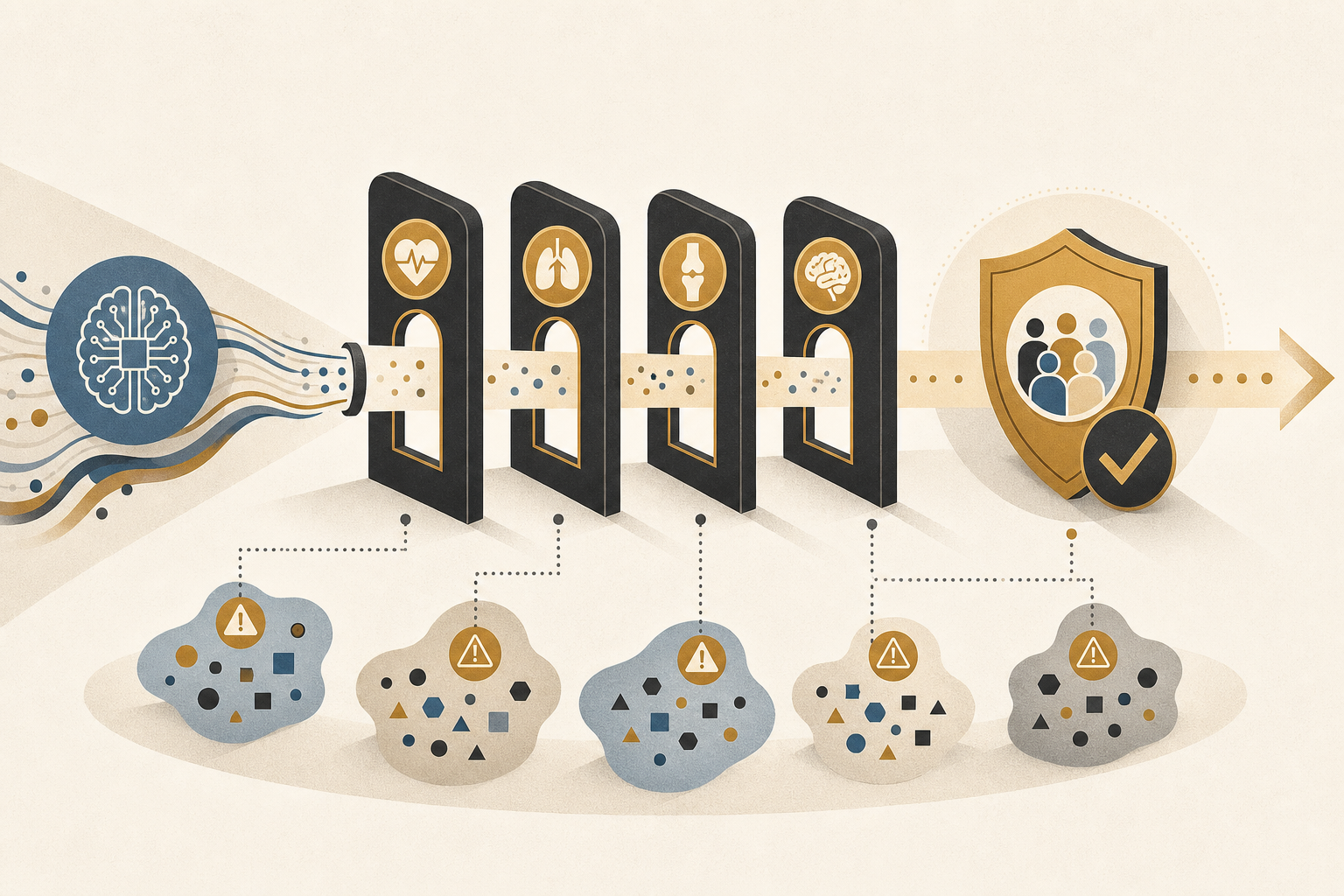
Why 'High Average Score' Is Not a Trustworthy Safety Standard for Medical AI
100 medical professionals evaluated medical LLMs across 9 domains and 690 adversarially designed test cases. High average accuracy masked serious failures in specific scenarios. LLM judges missed safety concerns that human experts caught. And changing patient demographics alone amplified errors by 10–20%. Here is how to rethink medical AI procurement.

2026 / 06 / 07
Financial Fraud Peaks When Alzheimer's Patients Miss Their Medication
Cognitive vulnerability in Alzheimer's patients fluctuates with medication adherence — and financial exploiters may be exploiting exactly those windows. Integrating medication records with transaction patterns pushed recall during non-adherent periods from 0.74 to 0.91. Here is what this means for elder financial protection.
2026 / 06 / 07
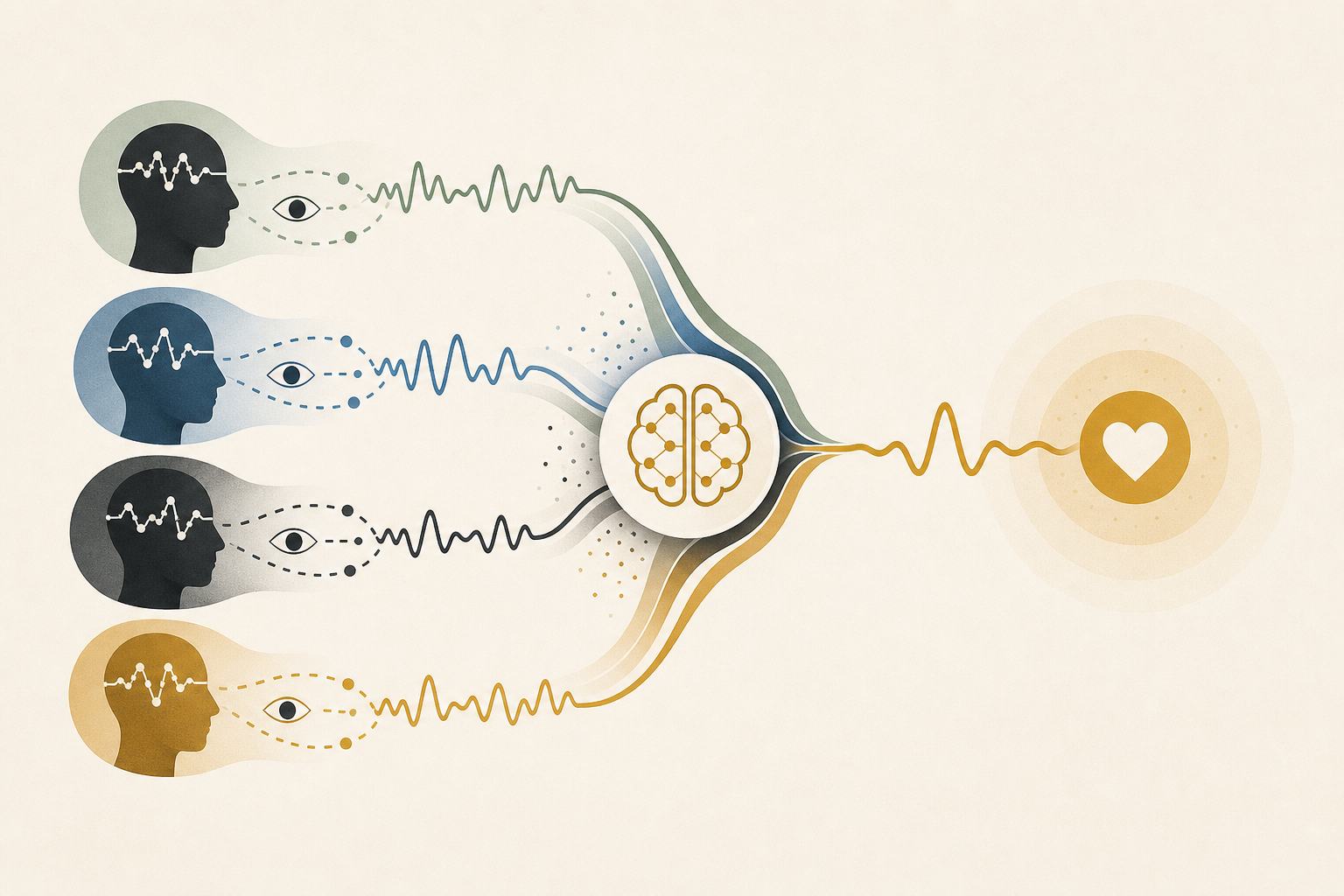
Combining EEG and Eye-Tracking: Can Emotion Recognition Finally Work Across Different People?
Subject-to-subject and session-to-session domain shift has long been the biggest barrier to deploying emotion recognition in the real world. UF-AMA clears that bar through confidence-based filtering and multi-stage domain adaptation — with practical implications for call centers and remote hiring.

2026 / 06 / 06
Can You Tell Whether an AI Agent Failed at Planning or Execution?
When an LLM agent fails, most evaluations can't tell you whether planning or execution was the problem. APB is a diagnostic benchmark designed to break that black box open — and it has direct implications for how organizations should select agents before deploying them.

2026 / 06 / 06
Personalizing LLMs at Scale Without Per-User Models
Two dominant personalization approaches both hit walls at scale: retrieval quality dependency and storage costs that grow with user count. TAP-PER encodes user preferences into compact prefix embeddings, bypassing both.

2026 / 06 / 06
Why AI Agents Need a Layer That Can Stop Them Before They Act
The risk with LLM agents isn't that they propose wrong actions — it's that wrong proposals get executed. The Organizational Control Layer concept offers a practical governance design for anyone deploying AI in operational workflows.
2026 / 06 / 06
Label-Free User Profiling: What BUMP Means for LLM Personalization
No task labels, no manual annotation. A self-supervised framework that generates natural-language user profiles from behavior logs alone could make LLM personalization accessible at scales where it previously wasn't cost-effective.

2026 / 06 / 06
Should We Suppress or Unleash AI Emotion?
LLMs are deliberately trained to suppress emotional expression. Is that the right call? A new study using self-rewarding reinforcement learning asks whether giving AI the ability to "feel" might actually make it more robust.

2026 / 06 / 05
You Can Develop AI Emotional Dependence Without Even Trying
You don't need a companion app for AI emotional dependence to take hold. A 28-day longitudinal study shows that everyday interactions with general-purpose AI quietly shift how we seek emotional support from other humans.

2026 / 06 / 05
Why a High Benchmark Score Does Not Mean an LLM Is Clinically Useful
The best LLMs score in the 90s on static medical QA benchmarks. In dynamic clinical conversations, the same models achieve 40–60%. MedSP1000 reveals a critical gap — and changes what health AI procurement should actually measure.

2026 / 06 / 05
A 'Trust Certificate' for AI Agents Before They Go Live
Deploying AI agents in regulated industries like finance, healthcare, and law raises a hard question: how do you verify compliance before going live? A new ontology-grounded framework offers a credible answer — and a new basis for AI procurement.
2026 / 06 / 05
Why Debiasing LLMs with Reinforcement Learning Is So Hard — And How BiasGRPO Fixes It
Standard RLHF becomes unstable when applied to social bias mitigation because bias evaluation is subjective and reward signals are noisy. BiasGRPO uses group-relative policy optimization to stabilize the training — and lays the technical groundwork for 'fairness-certified AI' in high-stakes applications.

2026 / 06 / 05
How to Use External LLM APIs Without Sending Your Sensitive Data
For GDPR-constrained organizations, the barrier to using cloud LLMs is not cost — it's the risk of sending confidential data externally. SharedRequest solves this with a batch-mixing approach that achieves 20%+ better utility than differential privacy while cutting query costs by up to 5x.

2026 / 06 / 04
What an Image Makes You Feel Matters More Than What It Shows
The same image can trigger completely different emotional responses depending on cultural background. A new perception-modeling framework that captures both factual and affective dimensions of visual experience could reshape how global creative teams pre-screen their visuals.

2026 / 06 / 04
AI Is Most Valuable for Work People Know They Should Do But Keep Putting Off
A randomized controlled trial with 11 TAs and 88 students found that AI draft assistance increased feedback provision by 10.8 percentage points — without quality loss or increased time. The mechanism wasn't efficiency. It was reduced initiation friction. Here's why that distinction matters for how you deploy AI at work.

2026 / 06 / 04
One Sentence About AI's Limitations Makes People Use It More Carefully
A randomized experiment with 252 students found that simply warning users about AI fallibility significantly increased help-seeking behavior. No system changes. No training program. Just a disclosure. Here's what this means for how organizations deploy AI tools.

2026 / 06 / 04
AI Overuse at Work Is a Competitive Environment Problem, Not a Personal Discipline Problem
A study of 396 generative AI users found that social comparison orientation — not individual personality — drives problematic AI use through FoMO and perceived replaceability. The design implication: competitive workplace structures create the trap, and organizational design can dismantle it.

2026 / 06 / 04
Same Symptoms, Different Urgency: The Gender Bias in LLM Medical Triage You Need to Know About
A study testing Gemini, Claude, and GPT with identical neurological symptom profiles — changing only gender and age — found dramatically lower emergency referral rates for young women. The mechanism isn't random error. It's epidemiologically-driven diagnostic substitution. And it's consistent across all three model families.

2026 / 06 / 03
A/B Testing That Generates Its Own Next Round — Field Experiments with AI Agents
An AI agent learned from 700K+ patient visit field experiment data and auto-generated 17 new message variants for round two. The top AI-generated message hit 69.8% CTR, outperforming expert-designed messages. The key finding: LLMs without real data couldn't predict effective interventions. Data is what makes the loop work.

2026 / 06 / 03
Highly Capable AI Might Be Damaging Your Team — A Study on Workplace Perception
An experiment with 50 participants found that low-competency, low-proactivity AI produced better outcomes for employee ownership, job meaningfulness, and team dynamics than the high-performing alternative. For HR and AI implementation leaders, the design implication is significant.

2026 / 06 / 03
Your Training Curriculum and Job Requirements Are Probably Out of Sync — NLP Can Now Measure the Gap
An NLP pipeline that auto-extracts skills from curricula and job postings, maps them to the ESCO standard classification, and quantifies the gap by category is now available as a research framework. The structure translates directly to corporate L&D and hiring strategy.
2026 / 06 / 03
Stop Making Users Re-Explain Everything: A Knowledge Architecture for Financial AI
InKH, an interaction-native knowledge harness for financial LLM agents, absorbs session context passively and retrieves it via temporal graph memory — achieving task quality 0.815, latency under 900ms, and 96% reduction in stale knowledge use. The design principle is broadly applicable wherever users are currently paying the complexity cost that systems should absorb.

2026 / 06 / 03
Can VR Actually Build Empathy? What Face-Tracking in a Narrative Game Suggests
A VR system called Rekindle uses real-time face-tracking to sense a player's emotional state and weave it directly into the narrative's shape — not just its difficulty. For anyone designing empathy training or affective experience, the design philosophy shift here is worth examining.

2026 / 06 / 02
Is AI Empathy Real or Manipulative? A Signal-Cost Framework for Getting It Right
When an AI expresses empathy, is it actually appropriate for the moment? A new framework drawing on economic signaling theory offers a way to measure — and design for — the difference between over-empathy and cold indifference. A 5-minute read for chatbot, HR tech, and CX teams.

2026 / 06 / 02
Can You Package a Veteran's Expertise Before They Retire? COLLEAGUE.SKILL Says Yes
A framework called COLLEAGUE.SKILL automatically converts experts' tacit knowledge — procedural know-how, mental models, decision heuristics — into structured AI skill packages that can be edited, versioned, and transferred to other agents. For L&D, knowledge management, and AI implementation teams, this is one of the more practically grounded ideas in tacit knowledge transfer.

2026 / 06 / 02
How Should Hospitals Choose Their Clinical AI? EHRBench Offers a Starting Answer
A new benchmark called EHRBench auto-generates over one million clinical QA pairs from electronic health records and evaluates more than 30 LLMs across three core clinical tasks. For hospital procurement teams, healthcare AI vendors, and regulatory bodies, it's the closest thing yet to a standard evaluation axis for clinical AI selection.

2026 / 06 / 02
Can We Measure How Emotionally Attached Users Are to AI? HAABI Says Yes
A new measurement scale called HAABI can quantify the emotional bond users form with conversational AI — across four dimensions, validated with 673 participants. For AI product managers, HR tech teams, and CX designers, this opens the door to KPI-based monitoring of both over-dependency and disengagement risk.

2026 / 06 / 02
Chat UI vs. Dashboard: What 134 Managers' Data Actually Says
An experiment with 134 manufacturing managers compared LLM-based conversational interfaces against graphical dashboards across tasks of varying complexity. The results offer a clearer picture of when to use which — and why neither is a replacement for the other. A 5-minute read for DX, ERP, and BI tool teams.

2026 / 06 / 01
Autonomous Driving Got Both Rules and Intuition ── ADRD's Case for Interpretable LLM Control
The wall that pure reinforcement learning and standalone LLMs couldn't break through in autonomous driving has been tackled by combining rule-based decision systems with LLM reasoning. ADRD achieves interpretability, response speed, and driving performance simultaneously — here's what that means for automotive and mobility teams.

2026 / 06 / 01
Breaking the Cultural Wall in Emotion AI ── What 61% Bias Reduction Actually Means
When emotion AI sounds warm to American users but cold to Japanese users, that's not an accuracy problem — it's a structural bias problem. A 2026 paper introducing the Affective-CARA framework cut cultural expression bias by 61% using a knowledge graph approach. Here's what that means for global HR and CX teams.

2026 / 06 / 01
Cars Don't Need an LLM — The Era of Lightweight Models That Learn the 'Cognitive Chain'
'Slap GPT on the car and win' is already outdated. Why data-center-style designs break inside the cabin, and why lightweight models that embed cognitive science are stronger — a 5-minute brief for automotive and mobility leaders.

2026 / 06 / 01
Is AI Emotion Real? ── The Discovery of an Emotion Space That Matches Across Languages
The emotional map that LLMs construct structurally overlaps with the one humans use. A 2026 study validated this across multiple languages and cultures — and the findings give global emotion AI deployments a more solid empirical foundation than before.

2026 / 06 / 01
When Everyone Can 'Write Well' With AI, Where Does an Organization Measure Individuality?
In an era where anyone can mass-produce polished prose with AI, the thinking of the whole organization is quietly being homogenized. A 5-minute read from the latest research on argument rarity and our emotion-AI perspective.

2026 / 06 / 01
Emotion AI Went Team-Based ── Why One LLM Can't Do It Alone
Why does a single LLM keep hitting a wall when it comes to understanding emotions? A 2026 survey revealed a clear breakthrough: collaborative architectures where multiple LLMs divide the work. Here's what it means for product teams in 5 minutes.

2026 / 06 / 01
An AI That Takes “Thank You” at Face Value Will Lose Your Most Important Customers
When a customer says “well done,” is it praise or sarcasm? The moment your AI mistakes one for the other, NPS goes up, improvement priorities go down, and the genuinely angry customers leave in silence. Five minutes for CX leaders, drawn from two recent sarcasm-recognition papers.

2026 / 06 / 01
“Outrage Wins Clicks” Is Already Outdated — The AI That Tones Down Intensity Without Changing Meaning
What comes after a decade of media optimized for anger, anxiety, and outrage? An AI that preserves meaning while dialing down emotional intensity is quietly redrawing the competitive map for media, advertising, and content platforms. Five minutes.

2026 / 06 / 01
Why Emotion AI Needs Its Own Rules
Should we regulate emotion AI — the kind deployed in healthcare, education, and mental health — with the same frameworks we use for general AI? A 23-author interdisciplinary report says no, and lays out 10 concrete proposals for what's needed instead.

2026 / 06 / 01
Emotion-AI Projects Probably Die in the Gaps Between Layers
Most enterprise emotion-AI projects fail not because of technology, vendors, or the field, but because responsibility falls into the gaps between layers. A six-layer model, five design criteria, and the concept of emotional sovereignty — a 5-minute read for executives.

2026 / 06 / 01
Before 'AI Governance' Lands on the CEO's Desk — Just 3 Things
LLMs are no longer an IT-only matter. They are quietly shaping the language used in politics, education, and the workplace. Three control points an executive should keep their hand on — data, model selection, output review. A 5-minute guide.

2026 / 06 / 01
I Made GPT Take the Real-Estate Exam, and Saw the Shape of the Future of Licensed Professions
What happens when GPT-3.5 and GPT-4 take Japan's licensed real-estate broker exam. A 5-minute take, for legal tech, in-house legal, and licensed professionals, on how to turn an 'AI that can't pass' into a tool that makes pass-holders 1.5× more productive.
2026 / 06 / 01
ChatGPT Quietly Changes Its Tone Depending on the Country Name
'Russia,' 'Ukraine,' 'Iran,' 'the U.S.' — swap a country name and an LLM's output sentiment quietly tilts. A 5-minute take, for global PR, compliance, and government relations, on how to face geopolitical bias.

2026 / 06 / 01
One AI Per Employee: How HR Quietly Changes
From 'roll out the same HR tool to everyone' to 'each employee has a personal AI that talks with the org AI.' A 5-minute take on the two-layer design for next-generation HR — for HR leads, organization developers, and executives.

2026 / 06 / 01
Emotion Data Is Shifting From “Collect” to “Create” — A Third Option Called Synthetic Data
Emotion-labeled data is hard to collect because of annotator burden, privacy, and representativeness. Three recent papers show that pairing domain knowledge with LLMs can resolve ethics and cost at the same time. Five minutes for data-ops leaders.

2026 / 06 / 01
A 4.5-Star and a 4.5-Star Are Not the Same — The Resolution Story for Emotion Data in Tourism
Reviews, social posts, photo captions. In an era where LLMs decode the fragments of emotion travelers leave behind, how do you act on a satisfaction structure that star ratings miss? Five minutes for tourism, municipal, and hospitality leaders.

2026 / 06 / 01
The Emotion AI That Says '92% Confident' Is the Most Dangerous One
Emotion-reading AI keeps answering confidently in moments where it should hesitate. What happens in CX, support, and SaaS operations — a 5-minute take from three uncertainty papers and an emotion-AI lens.

2026 / 06 / 01
AI That Measures “How the Workplace Feels” — Support and Surveillance Are Two Sides of the Same Coin
AI that visualizes employees' psychological states is quietly spreading through HR and organizational development. From three recent studies, here's a five-minute brief on “designs that do not feel like surveillance,” “connecting measurement to intervention,” and “measuring emotion without dehumanizing the person” — for HR and executive leadership.
2026 / 05 / 31
Your Company's AI Is Quietly Guessing 'Whose Name This Is'
Global CRM, hiring AI, credit scoring — processes that infer nationality from a customer's name are quietly spreading. What is going on behind the convenience? A 5-minute take from the latest research and an emotion-AI lens.