Column
Combining EEG and Eye-Tracking: Can Emotion Recognition Finally Work Across Different People?
Subject-to-subject and session-to-session domain shift has long been the biggest barrier to deploying emotion recognition in the real world. UF-AMA clears that bar through confidence-based filtering and multi-stage domain adaptation — with practical implications for call centers and remote hiring.
Hello. This is Keito Inoshita from Affectosphere Group.
When you try to deploy an emotion recognition system in a real production environment, you always hit the same wall.
A model trained in the lab falls apart the moment it encounters slightly different people, slightly different days, or slightly different conditions. This is called domain shift, and it has been a stubborn obstacle for affective AI research for years.
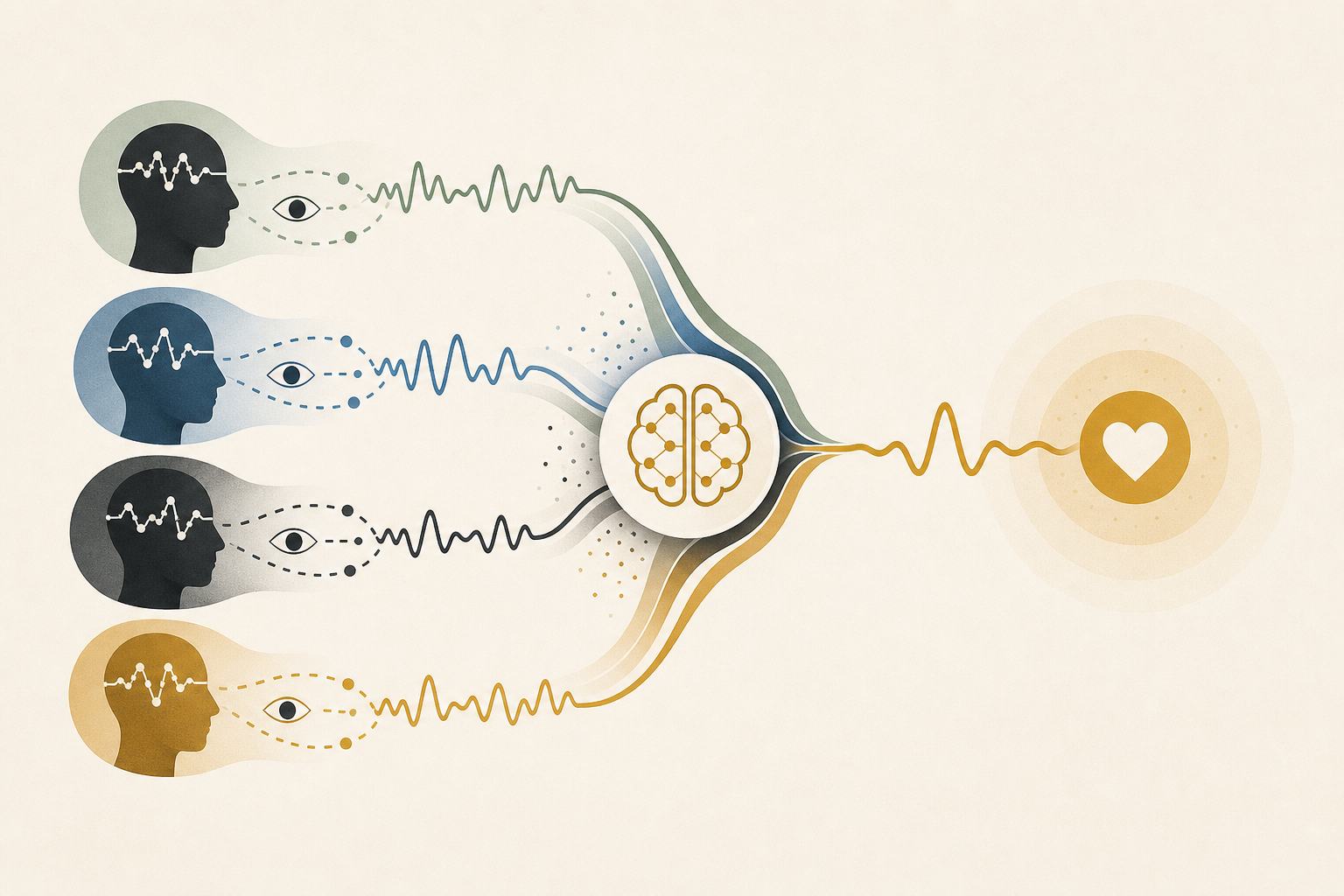
A study published on arXiv in May 2026 (Zheng Wang, Shuo Wang, Junhong Wang; arXiv:2606.00170) takes this problem head-on. The proposed framework, UF-AMA, combines EEG (brainwave) signals with eye-tracking data and achieves state-of-the-art accuracy on the SEED and SEED-IV benchmark datasets.
Three takeaways for today
- Combining EEG with eye-tracking improves robustness compared to either modality alone.
- Confidence-based data filtering plus multi-stage domain adaptation compensates for both cross-subject and cross-session variability.
- The design philosophy directly addresses real-world deployment scenarios where the user population constantly changes.
① Why multimodal, and why these two modalities
There are broadly two approaches in emotion recognition research.
One uses external signals — facial expressions, voice, text. The other uses physiological signals like EEG. The strength of physiological signals is that they are hard to deliberately control. Facial expressions and voices can be masked, but EEG is difficult to fake. This makes it a more direct window into internal emotional states.
EEG alone can be information-sparse in some conditions. Since emotion is a composite phenomenon, adding eye-tracking — which captures where attention is directed — lets the system simultaneously observe brain state and external focus. That is why UF-AMA includes both.
The key is that the two modalities are not simply concatenated. Adaptive Multimodal Alignment dynamically weights how much to trust each signal, constructing the features used for final emotion estimation. This flexibility is what makes it robust to variability across sessions and subjects.
② How domain shift is overcome
Domain adaptation is the central engineering challenge UF-AMA addresses.
There are two primary forms of domain shift in emotion recognition.
Subject-to-subject shift: the same emotional stimulus produces different EEG patterns in different individuals. A model trained on person A does not transfer reliably to person B.
Session-to-session shift: EEG features change across time even for the same person — due to fatigue, mood baseline, or electrode placement variation. A model trained on Monday may lose accuracy by Friday.
UF-AMA handles this in two stages. First, confidence-aware filtering selects source-domain samples that are likely to generalize to the target domain. Then multi-stage domain adaptation progressively aligns the feature distribution toward the target.
This combination drives the benchmark results on SEED and SEED-IV.
③ If you were to deploy this — call centers or remote interviews?
Let me think through what this framework suggests for real-world business deployment.
One of the most immediately plausible use cases is agent emotion monitoring in call centers.
Call centers are emotionally demanding environments. Agents experiencing emotional burnout are difficult for supervisors to identify in real time across an entire team. A continuous monitoring system using EEG + eye-tracking wearables, built on a framework like UF-AMA, could detect early indicators of emotional exhaustion and surface them as alerts.
The specific value of UF-AMA here is the “works even when the person changes” property. As agents rotate across shifts and teams, the system can adapt to each individual without requiring full retraining. KPIs might include detection accuracy for burnout incidents, or correlation between early alerts and subsequent customer complaint rates.
A similar logic applies to remote hiring. Both interviewers and candidates vary in condition from day to day. Systems that depend heavily on session-specific calibration will produce noisy results. Multi-stage domain adaptation gives a structural advantage.
To be clear, the costs and consent challenges of EEG wearables in workplace settings are real. The near-term question is not “deploy this company-wide” but “which department and use case is worth a pilot.” This is the design thinking this research enables.
Robustness, not just accuracy
What makes this research interesting is that it centers robustness rather than performance on a clean benchmark.
A lot of emotion recognition papers compete on accuracy with new architectures. But whether a system works in practice usually depends on how it handles domain shift, not how it performs on the test set it was trained for.
UF-AMA improves benchmark numbers while explicitly foregrounding domain adaptation. As an affective AI researcher, I think this design priority matters more than the leaderboard position itself.
The bridge from “works in a lab” to “works in the field” is still being built. This is a useful brick.
That’s it for today!
Reference
- Zheng Wang, Shuo Wang, Junhong Wang (2026). UF-AMA: A Unified Framework for Cross-Domain Emotion Recognition via Adaptive Multimodal Alignment. arXiv preprint.
* This article was written in part with AI assistance and may contain inaccuracies.