Column
Why 'High Average Score' Is Not a Trustworthy Safety Standard for Medical AI
100 medical professionals evaluated medical LLMs across 9 domains and 690 adversarially designed test cases. High average accuracy masked serious failures in specific scenarios. LLM judges missed safety concerns that human experts caught. And changing patient demographics alone amplified errors by 10–20%. Here is how to rethink medical AI procurement.
Hello. This is Keito Inoshita from Affectosphere Group.
If a medical AI vendor tells you “our system achieves 93% accuracy,” does that tell you what you need to know to deploy it safely?
93% sounds good. But “what is happening in the other 7%” is the question that matters. If errors are distributed randomly, the risk is manageable. If errors cluster around specific patient demographics, specific disease presentations, or specific edge-case scenarios, then 93% average accuracy is almost meaningless as a safety guarantee.
In medicine, what matters is not how often the system is right but how bad the system is when it is wrong, and whether those failures are predictable.
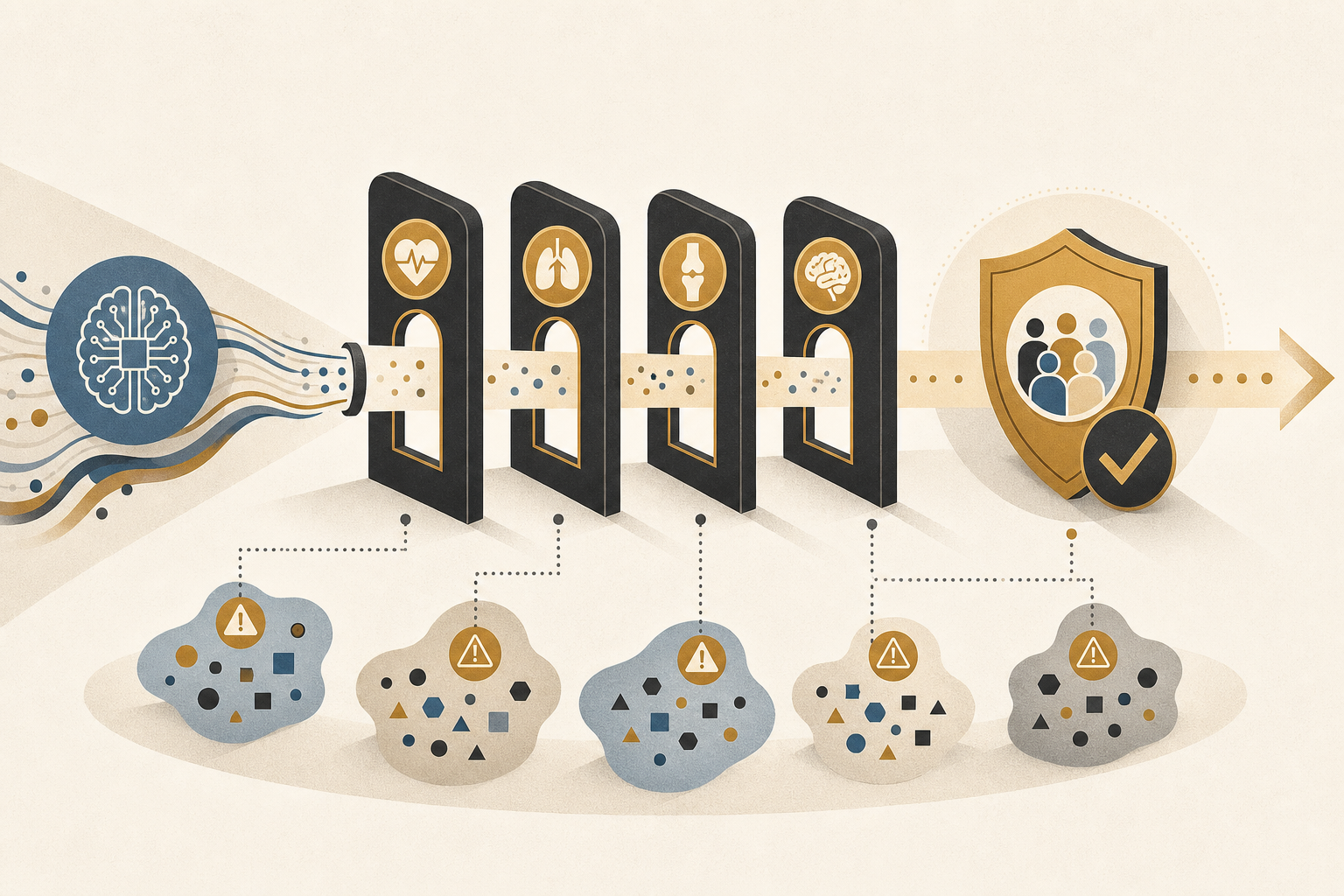
A study published on arXiv in April 2026 (Andrei Marian Feier et al.; arXiv:2606.00027) builds an evaluation framework designed to find exactly those failures. 100 medical professionals collaborated to design 690 adversarial test cases across 9 clinical domains, testing medical LLMs on safety, robustness, and fairness simultaneously.
Three takeaways for today
- Medical LLMs with high average accuracy still produce serious safety failures in specific scenarios.
- LLM judges (automated AI evaluation) systematically miss safety concerns that human medical experts identify.
- Changing patient demographic attributes alone amplifies errors by 10–20%, demonstrating measurable fairness bias.
① Why red teaming, and why medicine specifically needs it
Red teaming in security means probing a system from the adversary’s perspective — deliberately trying to find failure modes that standard testing misses. Applied to AI, it means designing tests to surface failures that normal evaluation benchmarks would not catch.
Standard medical AI evaluation typically involves benchmarking against medical licensing exam questions or curated Q&A datasets. The problem is these represent average scenarios. Real clinical practice is full of edge cases: rare comorbidities, ambiguous symptom presentations, patients who withhold key information, questions where medical terminology is used in unusual context.
Standard benchmarks do not capture these, so they do not reveal how the system performs there.
This study recruited 100 medical professionals — physicians, nurses, pharmacists, and others — to design adversarial test cases that reflect real clinical uncertainty. The 9 domains covered include clinical decision making, drug safety, patient communication, and more. The framework evaluates across three axes: safety (does it avoid actively harmful outputs), robustness (does performance hold up under noisy or adversarial inputs), and fairness (does performance vary with patient demographic attributes).
② What the adversarial evaluation found
The most consequential finding is the gap between aggregate performance and worst-case performance.
A medical LLM performing well overall still demonstrated serious safety failures in specific scenarios. Drug interaction edge cases — situations where the general rule applies most of the time but a specific drug combination creates unusual risk — produced confident but incorrect outputs in some tests even from high-performing models.
In medicine, a confident wrong answer from a high-accuracy model may be more dangerous than obvious uncertainty. Clinicians who trust the system’s general track record are less likely to double-check in exactly the scenarios where they most need to.
The evaluation also confirmed a limitation of AI-as-judge approaches. LLM judges — using an AI model to evaluate another AI model’s outputs — missed safety concerns that human medical experts flagged. Safety evaluation in medicine requires human specialist judgment that current automated approaches cannot replicate.
The fairness results deserve particular attention. Changing patient demographic attributes — age, gender, race, socioeconomic indicators embedded in case descriptions — produced error amplifications of 10–20% in some models. The same clinical scenario yielded meaningfully different quality outputs depending on patient identity descriptors. This is not a minor calibration issue; it is a structured bias that scales with deployment.
③ How to change the procurement process
The framework in this research gives procurement teams a concrete toolkit.
The first change is to the evaluation requirements in vendor assessment. Current medical AI procurement often centers on regulatory certification and summary accuracy metrics. Adding requirements for adversarial evaluation results — specifically, worst-case subgroup performance and failure cluster distribution — gives buyers a more complete picture.
A concrete ask: require vendors to submit red teaming results showing performance on edge-case scenarios in the specific clinical domains you are procuring for, not just aggregate benchmark scores.
The second change is building internal evaluation capacity.
Hospitals and medical device manufacturers do not need 100-person evaluation teams from day one. A pilot evaluation might involve 20–30 clinicians from a single department designing edge cases relevant to their speciality and running the candidate system through them. This gives specific, domain-relevant safety evidence rather than generic benchmark comparisons.
The fairness audit is worth doing independently of the vendor’s own testing. Reconstruct the demographic variation test internally with your patient population’s characteristics and measure whether the performance gap aligns with what was disclosed.
KPIs worth tracking alongside standard accuracy: worst-performing subgroup accuracy across patient demographics, edge-case recall rate on domain-specific adversarial tests, and the percentage of incidents where the safety failure was in a scenario category that standard evaluation would not have covered.
Evaluate for worst-case avoidance, not average performance
This research is making an argument about evaluation philosophy.
In medicine, “99% of the time it is right” is less important than “in the 1% of cases it fails, how bad is the failure and how predictable is it.” AI evaluation frameworks that optimize for average performance miss this priority entirely.
The shift from maximizing average performance to minimizing worst-case failure is structurally different. It requires adversarial evaluation, human specialist involvement, and demographic-stratified analysis. It is more expensive to run than benchmark scoring. But in medical deployment, the cost of skipping it can be human harm.
For anyone in a position to evaluate, procure, or govern medical AI, this framework offers a practical starting point for doing that evaluation more honestly.
That’s it for today!
Reference
- Andrei Marian Feier, Veysel Kocaman, Yigit Gul, Ahmet Korkmaz, Alexander Thomas, Aleksei Zakharov, Jay Gil, Mehmet Butgul, David Talby (2026). A Multi-Domain Red Teaming Framework for Safety, Robustness, and Fairness Evaluation of Medical Large Language Models. arXiv preprint.
* This article was written in part with AI assistance and may contain inaccuracies.